Extended System Coherency - Part 3 – Increasing Performance and Introducing CoreLink CCI-500
Compared to CoreLink CCI-400, the CoreLink CCI-500 offers up to double the peak system bandwidth, a 30 percent processor memory performance increase, reduced system power, and high scalability and configurability. This blog will go into more detail on these benefits.
By Neil Parris

Chinese Version 中文版: 扩展系统一致性 - 第 3 部分 - 性能提升和 CoreLink CCI-500 简介
This week we announced the launch of a new suite of IP designed to enhance the premium mobile experience. A central part of this suite is the ARM CoreLink CCI-500 Cache Coherent Interconnect which builds on the market-leading success of the previous generation interconnect, extending the performance and lower power leadership of ARM systems.
One year on and over 47,000 views since my first blog on the subject we can see that system coherency remains an important factor for SoC design starts. CoreLink CCI-400 has seen great success, over 35 licensees across multiple applications from mobile big.LITTLE, to network infrastructure, digital TV and automotive infotainment. In all these applications there is a need for full coherency for multiple processor clusters, and IO coherency for accelerators and interfaces such as networking and PCIe.
Compared to CoreLink CCI-400, the CoreLink CCI-500 offers up to double the peak system bandwidth, a 30 percent processor memory performance increase, reduced system power, and high scalability and configurability to suit the needs of diverse applications. This blog will go into more detail on these benefits, but first I’ll give a quick recap of cache coherency and shared data.
Cache Coherency Recap
Cache coherency means that all components have the same view of shared memory. The first two parts of this blog series introduced the fundamentals of hardware cache coherency:
- Extended System Coherency - Part 1 - Cache Coherency Fundamentals
- Extended System Coherency - Part 2 - Implementation, big.LITTLE, GPU Compute and Enterprise
In my first blog I discussed the different methods of achieving cache coherency. Historically cache maintenance has required a lot of software overhead to clean and invalidate caches when moving any shared data between on-chip processing engines. AMBA 4 ACE and the CoreLink CCI-400 introduced hardware cache coherency which happens automatically without the need for software intervention. The second blog talks about applications such as big.LITTLE processing, where all big and LITTLE cores can be active at the same time, or a mix to meet the performance requirements.
Hardware Coherency and Snoops
The simplest implementation of cache coherency is to broadcast a snoop to all processor caches to locate shared data on-demand. When a cache receives a snoop request, it performs a tag array lookup to determine whether it has the data, and sends a reply accordingly.

For example in the image above we can see arrows showing snoops between big and LITTLE processor clusters, and from IO interfaces into both processor clusters. These snoops are required for accessing any shared data to ensure their caches are hardware cache coherent. In other words, to ensure that all processors and IO see the same consistent view of memory.
For most workloads the majority of lookups performed as a result of snoop requests will miss, that is they fail to find copies of the requested data in cache. This means that many snoop-induced lookups may be an unnecessary use of bandwidth and energy. Of course we have removed the much higher cost of software cache maintenance, but maybe we can optimize this further?
Introducing the Snoop Filter
This is where a snoop filter comes in. By integrating a snoop filter into the interconnect we can maintain a directory of processor cache contents and remove the need to broadcast snoops.
The principle of the snoop filter is as follows:
- A tag for all cached shared memory is stored in a directory in the interconnect (snoop filter)
- All shared accesses will look up in this snoop filter which has two possible responses:
- HIT –> data is on-chip, a vector is provided to point to the cluster with the data
- MISS –> go fetch from external memory

Power Benefits
The CoreLink CCI-500 provides a memory system power saving compared to previous generation interconnect due to the integrated snoop filter. This power saving is driven by the benefit of doing one central snoop lookup instead of many, and reducing external memory accesses for every snoop that hits in caches. Furthermore it may enable processor clusters to maintain a low power sleep state for longer while the snoop filter responds to coherency requests.
Performance Benefits
Mobile systems normally include asynchronous clock bridges for each processor cluster, and communicating across these bridges costs latency. It’s quicker, easier and lower power to communicate with the interconnect snoop filter instead. This reduced snoop latency can benefit processor performance, and benchmarking has shown a 30% improvement in memory intensive processor workloads. This can help make your mobile device faster, more responsive and accelerate productivity applications like video editing.
Also by reducing snoops, the processors in the system can focus their resources on processing performance and less on responding to snoops. In real terms it means that users will have an SoC that can deliver higher performance while requiring less power to do so.
Highly Scalable Solution
There is a consistent trend towards multi-cluster SoCs across a number of markets as design teams seek to unleash even more computing performance. Scaling to higher bandwidth systems with more processor clusters will show even greater benefits for the snoop filter. In fact it becomes essential when scaling performance beyond two processor clusters. CoreLink CCI-500 is highly scalable and supports configurations from 1 to 4 ACE interfaces (e.g. 1 to 4 processor clusters). While two-cluster big.LITTLE will remain the standard in mobile, the interconnect could support a future with more processors or indeed fully coherent GPU and accelerators. CoreLink CCI-500 fully supports the Heterogeneous System Architecture (HSA) concepts of full hardware coherency between processors and shared virtual memory by means of Distributed Virtual Memory (DVM) message transport. CoreLink CCI-400 has supported this since 2011, and CoreLink CCI-500 improves on this with more scalability and configurability.
Infrastructure networking and server applications already have high a proportion of shared memory accesses between processors and IO; the ARM CoreLink CCN Cache Coherent Network family of products already include integrated snoop filters to ensure the high performance and low latency expected by these applications. The CoreLink CCN family remain the highest performance coherent interconnect IP, supporting up to 12 clusters (48 cores), integrated level 3 system cache and clock speeds in excess of 1GHz. CoreLink CCI-500 is optimized for the performance and power envelope required for mobile and other power constrained applications. The complementary CoreLink NIC-400 Network Interconnect provides the low power, low latency ‘rest of SoC’ connectivity required for IO coherent requesters and the many 10’s or 100’s of peripherals and interfaces.
There is no 'one size fits all’ interconnect, instead ARM has a range of products optimized for the needs of each application.
Memory Bandwidth Demands Increasing
The performance of mobile devices including smartphone and tablet is increasing with every generation; in fact, tablets are replacing many laptop purchases. A key dimension of SoC performance is memory bandwidth, and this is being driven upwards by screen resolution, 3D gaming, multiple higher resolution cameras and very high resolution external displays. ‘Retina’ class display resolution is already commonplace on mobile devices and Ultra-HD 4K has been available on high end TVs for a couple of years. It is only a matter of time before we see 4K content appear in mobile devices.
To support this increase in memory bandwidth SoC vendors are looking to the latest low power double data rate (LPDDR) dynamic RAM (DRAM) technology. LPDDR3 is an established technology that was in 2013 consumer devices while LPDDR4 appeared in some 2014 devices and will continue to grow its rate of adoption in 2015 in both mobile and non-mobile applications. Each generation of LPDDR lowers the voltage but increases the interface frequency, net result: more bandwidth and lower energy per bit. A single 32 bit LPDDR4-3200 interface will offer 12.8GB/s which is typical on today’s premium smartphones.
CoreLink CCI-500 Offers Higher System Bandwidth
For mobile devices 32 bit memory channels are common ranging from single channel for lower cost, entry smartphones, through dual channel for high end smartphone, to quad channel for the highest performance tablets.
The CoreLink CCI-500 offers up to double the peak system bandwidth of CoreLink CCI-400 by supporting up to 4 memory channels. This could allow partners to build memory systems supporting 34GB per second and beyond which enables high performance, high resolution tablet computing. Of course scalability for multiple applications is important, and CoreLink CCI-500 can be configured from 1 to 4 memory channels to suit performance requirements.
Part of a Complete System
One of the biggest benefits of the ARM CoreLink Interconnect is that it has been developed, validated and optimized alongside our Cortex and Mali processor products with the high quality levels that our partners expect. This week’s launch also announced the Cortex-A72, ARM’s highest performance Cortex processor, the Mali-T880 GPU, high-end configuration for our latest Mali-V550 video and Mali-DP550 display IP and Artisan physical IP for 16 FinFet.
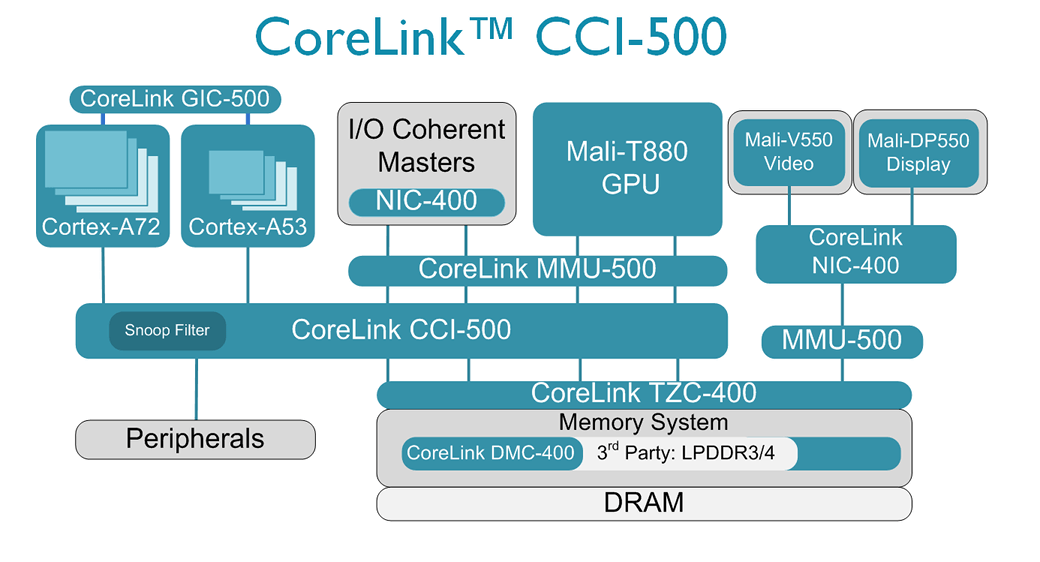
To complete the SoC ARM also offers a complete suite of system IP including CoreLink NIC-400 network interconnect for low power, low latency, end to end connectivity to the rest of the SoC, CoreLink MMU-500 system MMU for virtualization of IO and the CoreLink GIC-500 for management of interrupts across multiple clusters, not to mention CoreSight for debug and trace. Central to all of this is the CoreLink CCI-500 Cache Coherent Interconnect.
Summary
As we have seen with many other computing features that began in enterprise applications, mobile SoCs are rapidly catching up on the amount of shared traffic across the chip. It is proof that mobile computing power is still advancing steadily and incorporating many features that were only introduced to premium laptops a few years ago. The fact that mobile devices are now high performance devices in their own right should come as no surprise.
I for one look forward to seeing how a 2020 device will compare with today’s premium mobiles, and am looking forward to the challenge of making ARM technology that provides the infrastructure for the premium devices of tomorrow. What do you think devices will look like 5 years from now?
Links for further information:

By Neil Parris
Re-use is only permitted for informational and non-commercial or personal use only.
