DOT Neoverse N1: Accelerating DSP functions with the DOT Instructions
A practical example of using the DOT instructions from Armv8.4-A to optimize video workloads and common DSP algorithms.

In this blog, I describe the Armv8.4-A dot product instructions, which are available in Arm cores from Cortex-A75, Cortex-A55, and Neoverse N1 upwards. I introduce three use cases for these instructions; convolution, averaging, and taking the sum of absolute difference (SAD). I then show how we used these instructions to improve the performance of the libvpx (https://chromium.googlesource.com/webm/libvpx/ ) implementation of VP9. After reading this blog, I would like for you to understand the range of use cases that the DOT instructions can enable and then be able to apply them to digital signal processing code of your own.
The DOT instructions
Arm introduced the SDOT (Signed Dot Product) and UDOT (Unsigned Dot Product) instructions in the 2017 extensions to the Arm Architecture, collectively known as Armv8.4-A (https://community.arm.com/developer/ip-products/processors/b/processors-ip-blog/posts/introducing-2017s-extensions-to-the-arm-architecture).
These vector instructions operate on 32-bit elements within 64-bit or 128-bit vectors in the Neon instruction set, or within scalable vectors in the SVE2 instruction set. Within these 32-bit elements, we further divide in to four 8-bit elements. Each 8-bit element in each 32-bit element of the first vector is multiplied by the corresponding 8-bit element in the second vector, creating four sets of four products. Each group of four products are added to create a 32-bit sum, and this sum is accumulated into the 32-bit element of the destination vector. Conceptually, this is the vector inner, dot, or scalar product depending on your background. In this blog, I am calling it the dot product to match the instruction name. Graphically, this looks like:
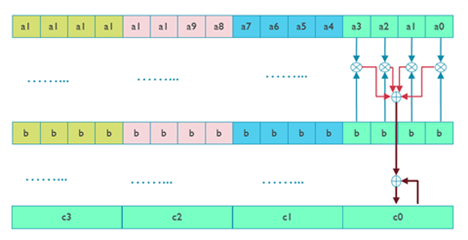
With thanks to an earlier blog from Jason Andrews.
The key insight needed for this blog is that the DOT instructions provide access to many multiply and accumulate operations every cycle. Arm’s latest processors, such as the Arm Cortex-X2 (https://developer.arm.com/documentation/PJDOC-466751330-14955/latest) and Arm Neoverse V1 (https://developer.arm.com/documentation/pjdoc466751330-9685/latest/) can compute four DOT product instructions in parallel. This allows us to multiply four 8-bit elements, in four 32-bit subvectors, across four 128-bit parallel operations every cycle. This works out at a very impressive sixty-four 8-bit multiply-and-(partial)-accumulate operations per cycle. This high throughput gives us motivation to look for opportunities to use these instructions outside of the scenario described previously. Looking beyond the vector dot product to other uses of 8-bit multiply and accumulate instead.
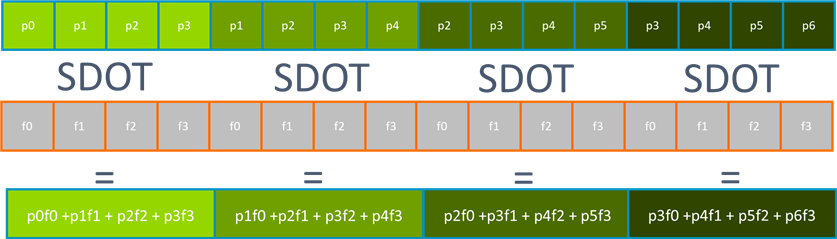
Calculating a one-dimensional image convolution
In a convolution, we want to perform a filter function over values either side of our current element and write back the result. One common filter function might be a weighted average of pixel values. To calculate this, we take a multiplication by a set of constants and sum them to a single value. With the appropriate data layout, this is a dot product between the input elements and the filter values. For example, if we want to compute the weighted average of eight 8-bit values we could use two rounds of the DOT instruction.
#include "arm_neon.h"
uint32x4_t weighted_average (uint8x16_t values_low,
uint8x16_t values_high,
uint8x8_t weights) {
uint32x4_t result = vdupq_n_u32 (0);
/* Low values multiplied by the first four weights. */
result = vdotq_lane_u32 (result, values_low, weights, 0);
/* Accumulate with high values multiplied by the next four weights. */
result = vdotq_lane_u32 (result, values_high, weights, 1);
return vshrq_n_u32 (result, 3);
}
This would generate the code outlined below (code generated with GCC 11.1 [see on Godbolt.org]).
weighted_average:
movi v3.2d, 0
udot v3.4s, v0.16b, v2.4b[0]
udot v3.4s, v1.16b, v2.4b[1]
ushr v0.4s, v3.4s, 3
ret
To get maximum parallelism out of the DOT instruction, we want to compute four output lanes at one time. Because we apply this filter, we can create an appropriate data layout by loading sixteen values at a time (using vld1q_u8) and then use the tbl instructions to rearrange data.
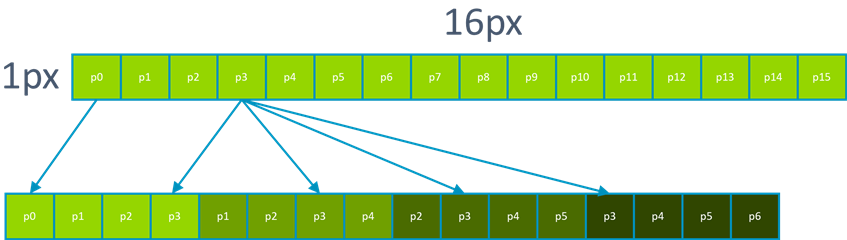
This allows us to construct the values_low variable from above. We can use another TBL to create the values_high variable.
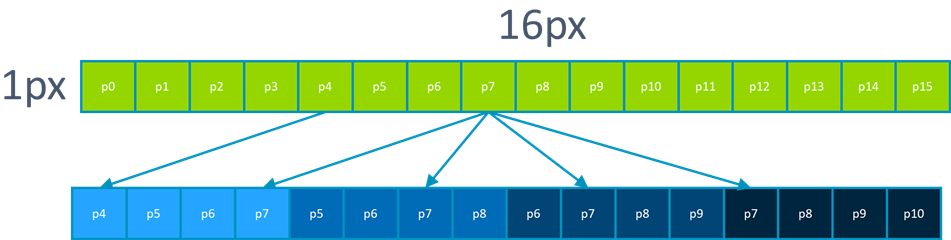
Now we can create our first four output values:

You may notice that the values_high that we have calculated are suitable to use as the values_low value for our next four pixels. We can use one more TBL to generate the next values_high and complete our calculation. We can then take our eight 32-bit results and reduce them back to eight 8-bit output values, using these three methods :
- vqmovn_u32 (to narrow a 32-bit value to a 16-bit value with saturation)
- vcombine_u16 (to pack two vectors of four 16-bit values and create one vector of eight 8-bit values)
- vqshrn_n_u16 (to saturate, narrow and shift a result)
Calculating an average
The average over a large array is just a weighted average where all weights are set to one! So we can use this same strategy multiplying by a vector of one to perform many widening additions in parallel. Because these widening additions always perform 16 parallel partial sums, this can sometimes be quicker than using pairs of other Armv8-A instructions like UADDL/UADDL2.
This would look like:
#include "arm_neon.h"
#define N 4096
// 16 elements in a vector
#define STRIDE (16)
unsigned int average (uint8_t *in) {
uint32x4_t sum = vmovq_n_u32 (0);
uint8x16_t ones = vmovq_n_u8 (1);
for (int i = 0; i < N; i += STRIDE) {
sum = vdotq_u32 (sum, vld1q_u8 (in), ones);
in += STRIDE;
};
return vaddvq_u32 (sum) / N;
}
Calculating the Sum of Absolute Differences
In a sum of absolute differences computation, we want to add together the absolute difference of each item in two arrays and return the result. In C code this would look like:
unsigned int sad (uint8_t *x, uint8_t *y) {
unsigned int result;
for (int i = 0; i < N; i++)
result += abs (x[i] - y[i]);
return result;
}
While Neon in Armv8.0-A contains instructions to accelerate the calculation of sum of absolute differences, these operate on each lane and must use a wider type for intermediate results. This means that we need more instructions on each loop iteration. The dot product instructions allow us to do this in one step. The trick is to remember that multiplication by 1 returns the same value. These two code generation strategies are shown in the following (code generated with GCC 11.1; [see on Godbolt.org]).
Without Dot Product
// During the loop
uabdl2 v0.8h, v1.16b, v2.16b
uabal v0.8h, v1.8b, v2.8b
uadalp v3.4s, v0.8h
// After the loop
addv s3, v3.4s
With Dot Product
// Before the loop
movi v3.16b, 0x1
// During the loop
abd v0.16b, v0.16b, v1.16b
udot v2.4s, v0.16b, v3.16b
// After the loop
addv s2, v2.4s
Not only does this optimization reduce the number of instructions executed within the loop body, but it can also avoid some resource utilization differences between the UABDL2/UABAL/UDALP instructions. This allows for better throughput of the summation operations, increasing overall performance. Further benefits can come from unrolling the loop multiple times, making even better use of available hardware parallelism. For example, we may rewrite this example using Neon intrinsics:
#include "arm_neon.h"
#define N 4096
/* Unroll 4x, calculate 16 items per vector. */
#define STRIDE (4 * 16)
/* Hm! Maybe not the clear example I intended! */
unsigned int sad_unrolled (uint8_t *x, uint8_t *y) {
uint32x4_t p0, p1, p2, p3;
uint8x16_t x0, x1, x2, x3;
uint8x16_t y0, y1, y2, y3;
p0 = p1 = p2 = p3 = vmovq_n_u32 (0);
uint8x16_t ones = vmovq_n_u8 (1);
for (int i = 0; i < N; i += STRIDE) {
x0 = vld1q_u8 (x + 0 );
x1 = vld1q_u8 (x + 16);
x2 = vld1q_u8 (x + 32);
x3 = vld1q_u8 (x + 48);
y0 = vld1q_u8 (y + 0 );
y1 = vld1q_u8 (y + 16);
y2 = vld1q_u8 (y + 32);
y3 = vld1q_u8 (y + 48);
p0 = vdotq_u32 (p0, vabdq_u8 (x0, y0), ones);
p1 = vdotq_u32 (p1, vabdq_u8 (x1, y1), ones);
p2 = vdotq_u32 (p2, vabdq_u8 (x2, y2), ones);
p3 = vdotq_u32 (p3, vabdq_u8 (x3, y3), ones);
x += STRIDE;
y += STRIDE;
};
return vaddvq_u32 (vaddq_u32 (vaddq_u32 (p0, p1), vaddq_u32 (p2, p3)));
This approach of unrolling to break dependency accumulation chains can provide great benefits across a range of Neon instructions, enabling more instruction level parallelism on Arm’s highest performance cores. This optimization will often need to be done by hand. This is because for saturating operations and floating-point operations, the order of operations can impact results and a compiler cannot normally know whether it is safe to accumulate in a different order.
Improving a real workload: VP9
Libvpx is an open-source library which provides reference implementations of the VP8 and VP9 video codecs. It is available as part of the WebM project and you can find the code on Google Git. As part of a project to accelerate VP9 performance on Arm’s latest cores, our open source performance team implemented some of the core functions of VP9’s encoder to make use of the DOT instructions.
We first use the standard Linux performance analysis tools perf record and perf report to understand where the encoder spends time. The experiments were completed using the Neoverse N1 SDP platform, with a Clang 12 compiler.
$ perf record ./vpxenc --codec=vp9 --height=1080 --width=1920 --fps=25/1 --limit=20
$ perf report
14.60% vpxenc-12a14913 vpxenc-12a149139 [.] vpx_convolve8_horiz_neon
7.43% vpxenc-12a14913 vpxenc-12a149139 [.] vp9_optimize_b
7.00% vpxenc-12a14913 vpxenc-12a149139 [.] vpx_convolve8_vert_neon
4.60% vpxenc-12a14913 vpxenc-12a149139 [.] vp9_diamond_search_sad_c
4.21% vpxenc-12a14913 vpxenc-12a149139 [.] vpx_sad16x16x4d_neon
3.19% vpxenc-12a14913 vpxenc-12a149139 [.] rd_pick_best_sub8x8_mode
2.90% vpxenc-12a14913 vpxenc-12a149139 [.] vpx_sad32x32x4d_neon
2.76% vpxenc-12a14913 vpxenc-12a149139 [.] vpx_quantize_b_neon
2.24% vpxenc-12a14913 vpxenc-12a149139 [.] vpx_quantize_b_32x32_neon
1.53% vpxenc-12a14913 vpxenc-12a149139 [.] vpx_variance32x32_neon
We can see that there already exist optimized paths in the code that make use of the Advanced SIMD architecture. Looking in more detail we can identify several target functions:
vpx_convolve8_horiz_neon, vpx_convolve8_vert_neonWe optimize these using the approach introduced in 'Calculating a one-dimensional image convolution' to use the DOT instructions to increase the available multiply and accumulate throughput available to us. Patches to VP9 performing this optimization can be found at [1] [2] [3]. Along with patches to improve the averaging versions of these convolutions: vpx_convolve8_avg_horiz_neon, vpx_convolve8_avg_vert_neon.
vpx_sad16x16x4d_neon, vpx_sad32x32x4d_neonWe optimized these using the approach described in 'Calculating the Sum of Absolute Differences'. Patches implementing this optimization can be found at [4].
vpx_variance32x32_neonWe optimized the variance functions using the approach described in 'Calculating an average'. Patches implementing this optimization can be found at [5].
Results
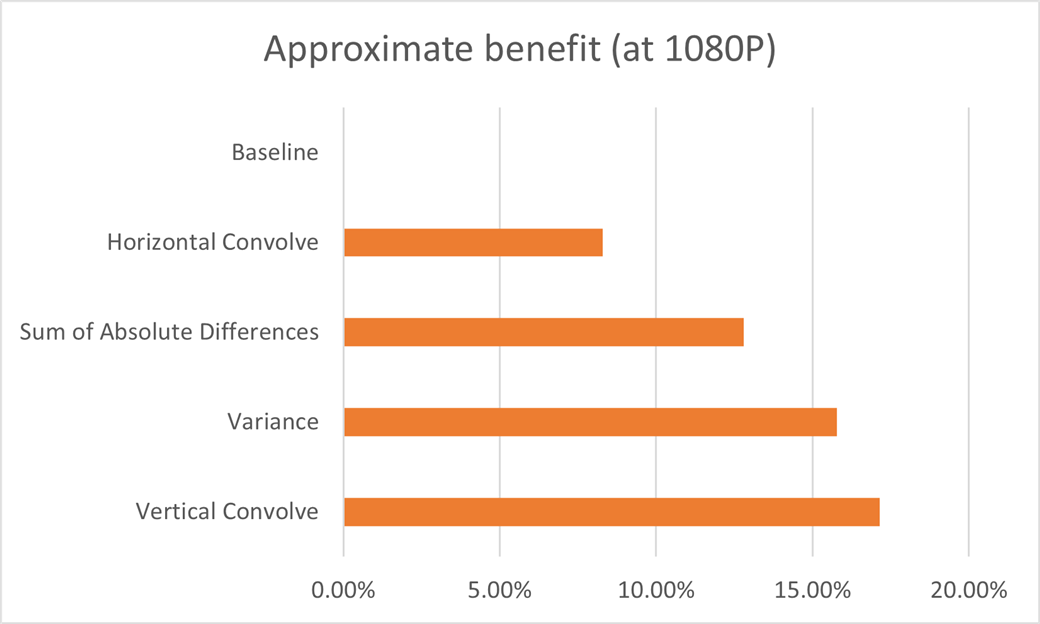
We were able to see an encode performance improvement of more than 17% at 1080p on the Neoverse N1 SDP platform. To achieve this we combined each of these optimization techniques, and contributed them back to the libvpx project. Exact results across Arm-based platforms depend on properties of the system, the compiler used, input/output resolution and file and encode settings
Conclusion
We have introduced three optimization techniques to make use of the DOT instructions from Armv8.4-A and shown how to use them in a popular video encode library. They improve performance by more than 15% on Arm’s latest hardware designs. These techniques can apply across a range of workloads. They increase the available throughput for widening multiply and accumulate for 8-bit data.
We would like to convey our thanks to
- Jonathan Wright at Arm for his hard work turning optimization ideas into real patches
- Russ Butler at Arm for his work benchmarking the results
- James Zern at Google for the community review of these patches and for merging them to the WebM
The Arm architecture is continually evolving to enable better performance and security for important code bases. Keeping up to date on the newest architecture features by using modern compilers, and optimized software built in partnership with open-source communities can greatly improve the already impressive results available when targeting the Arm architecture. Using our latest software, hardware, and architecture features, which have been designed to work better together at Arm, can provide amazing performance advantages for your most important workloads.
To learn more about how to optimize to make use of Arm Neon technology, visit the Neon pages on Arm Developer. On this site we have many more examples of how to use Arm’s SIMD architecture to unlock the performance of your devices.

Re-use is only permitted for informational and non-commerical or personal use only.
