Introducing the Scalable Matrix Extension for the Armv9-A Architecture
In this blog, read the details for Scalable Matrix Extension (SME). This is a new extension from the latest Arm Vision day announcement for Armv9-A.

The Arm architecture brought scalable vector processing from the supercomputer to the widest range of devices, resulting in most of the worlds computational workloads running on Arm architecture. Following the Vision Day announcement of Armv9-A, Arm is making available early technical details of a new extension to the Armv9-A architecture, the Scalable Matrix Extension (SME). SME is the latest in a planned series of architecture improvements to provide increasing support for matrix operations.
The purpose of this early disclosure is to inform and enable the OS and tools developer ecosystems. SME introduces a new programmer’s model and register state to support matrix operations that future additions through 2022 will build upon.
SME builds on the Scalable Vector Extensions (SVE and SVE2), adding new capabilities to efficiently process matrices. Key features include:
- Matrix tile storage
- Load, store, insert, and extract tile vectors, including on-the-fly transposition
- Outer product of SVE vectors
- Streaming SVE mode
Matrix multiplication on Arm
Matrix multiplications are an important part of many key workloads, such as scientific simulations, computer vision, some aspects of Machine Learning (ML), and Augmented Reality (AR). The Arm architecture has evolved over time, gaining features to improve the performance and efficiency of these operations: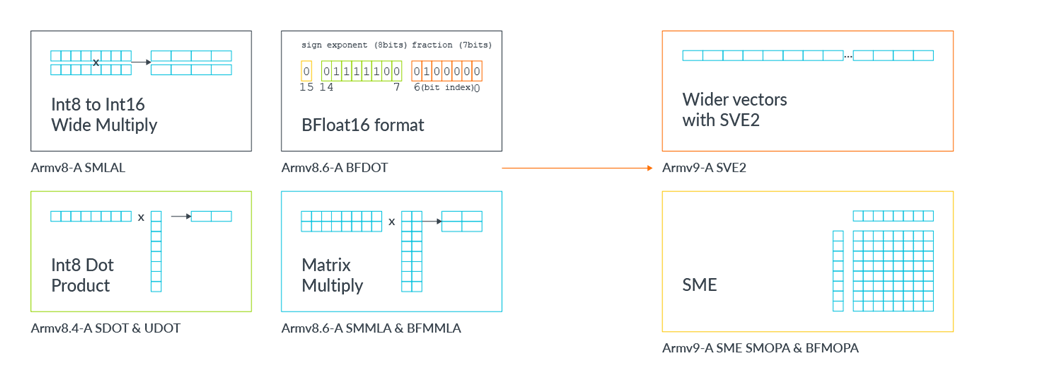
- Armv8.4-A: Support for 8-bit integer DOT product instructions
- Armv8.6-A: Support for in-vector integer & floating-point matrix-multiply instructions and the BFloat16 data type.
- Armv9-A: Support for wider vectors in SVE2.
SME is the next step in this journey, enabling a significant increase in CPU matrix processing throughput and efficiency.
SME and matrix multiplication
To perform a matrix multiplication, a simple implementation is a triple nested loop algorithm as shown in the following graphic: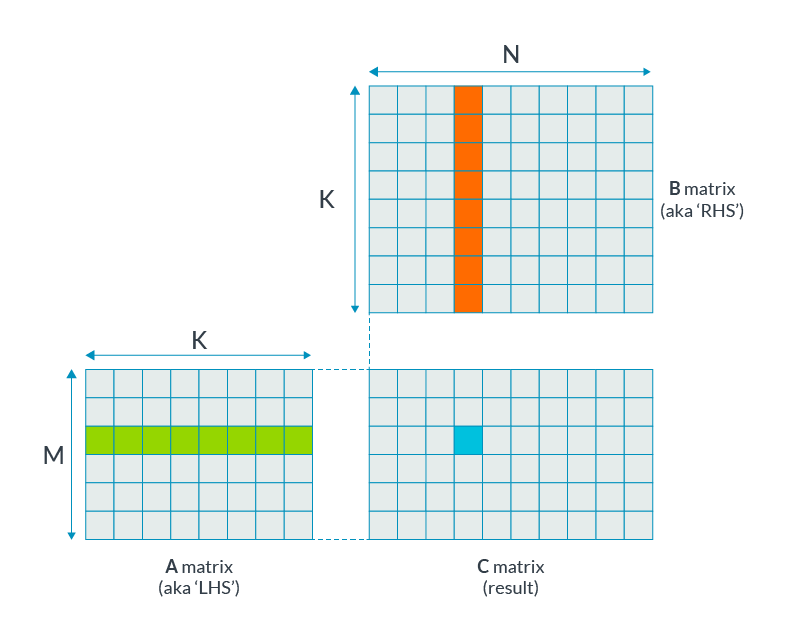
for m in 0..M-1
for n in 0..N-1
C[m, n] = 0;
for k in 0..K-1
C[m, n] += A[m, k] * B[k, n]
This approach would give a multiply to load ratio of 1:2, that is 1 multiply per two element loads. To improve efficiency and throughput, we need to increase this ratio. One way to do this is by calculating more than one result at a time, for example: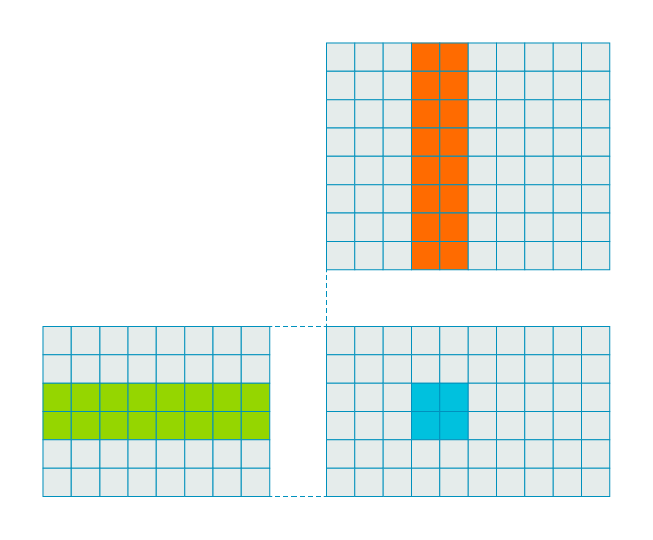
In the previous example, by calculating a block of four results the multiply to load ratio improves to 1:1. That is, four loads are required to compute four multiplies.
SME is based on an outer-product engine, which takes the idea of generating multiple results per load further still: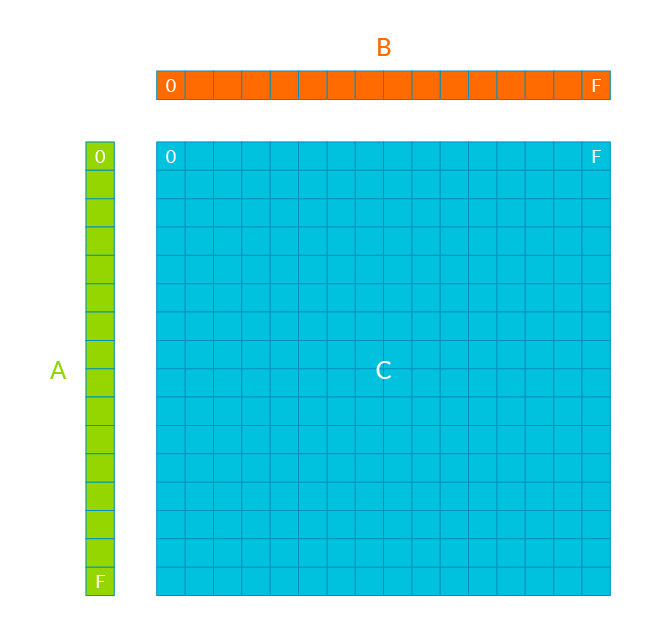
An outer product of vectors A[H] ⨷ B[W] is calculated, generating an HxW matrix which is accumulated into a matrix tile C[H×W]. A full matrix multiplication of A[HxK] and B[KxW] is calculated by iterating over the columns in A and the rows in B, accumulating into C.
SME is a scalable architecture, allowing implementation choice on the width of vectors supported. The multiply to load ratio depends on the implemented width. For example, a 512-bit vector implementation with 32-bit data would give a multiply to vector load ratio of 256:2. This increases to 256:1 when four output tiles can be computed from four input vectors.
Outer products can also be used to construct other high-level matrix operations such as matrix inversion, filters, and linear equation solvers.
SME and SVE2
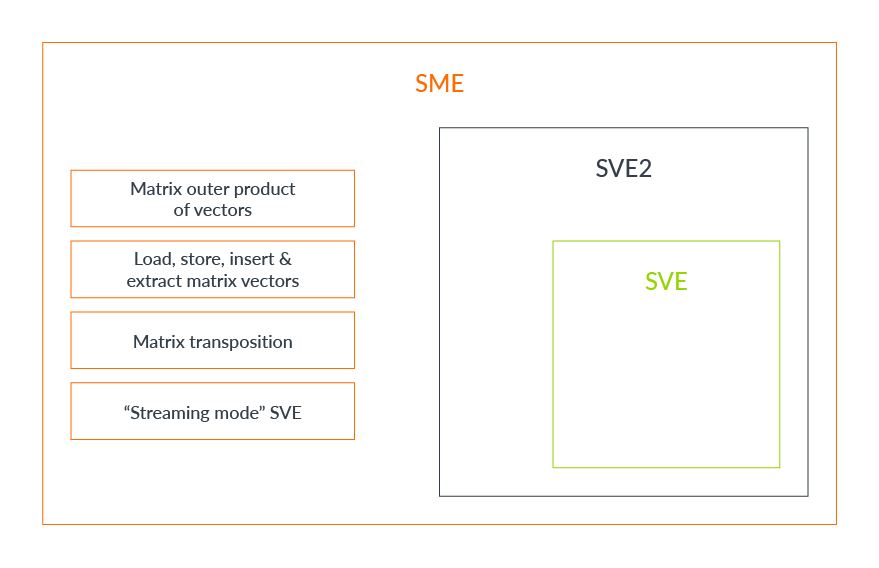
A new operating mode is added, Streaming SVE Mode. When in Streaming SVE Mode, the new SME storage and instructions are available, as well as significant subset of the existing SVE2 instructions. When not in Streaming SVE mode, behavior is unchanged from SVE2. Applications can switch between operating modes depending on what is needed.
Having a separate mode for SME operations allows an implementation to support different vector lengths for streaming and non-streaming processing within the same application. For example, an implementation might choose to support a larger vector length in Streaming SVE mode, with the hardware optimized for streaming, throughput-oriented operation.
Find out more
Full Instruction Set and System register information for SME is available with our technical webpages. A supplement to the Arm Architecture Reference Manual (ArmARM), documenting SME, is due for release at the end of this year. We also plan to release supporting materials and examples as part of the Learn the Architecture program of guides in 2022.

Re-use is only permitted for informational and non-commerical or personal use only.
