Developments in the Arm A-Profile Architecture: Armv8.6-A
The Arm Architecture is continually evolving to meet the needs of our ecosystem partners. This blog gives a high-level overview of some of the changes being introduced in Armv8.6-A. The enhancements to the architecture provide more efficient processi...

The Arm Architecture is continually evolving to meet the needs of our ecosystem partners. This blog gives a high-level overview of some of the changes being introduced in Armv8.6-A.
The enhancements to the architecture provide more efficient processing and better enable new areas such as Neural Networks (NN) for Machine Learning (ML). Both General Matrix Multiply (GEMM) and BFloat 16 provide major improvements in this area. We introduce further security features with enhancements to pointer authentication support.
Full Instruction Set and System Register information will be available via our technical webpages. The complete Armv8-A Architecture Reference Manual (ArmARM), documenting Armv8.6-A and earlier functionality, is due for release next year. XML releases will be available soon and we will link to those when available.
Details of previous updates to the A-Profile architecture are available here: Armv8.1-A, Armv8.2-A, Armv8.3-A, Armv8.4-A, and Armv8.5-A.
Vector and floating-point focused enhancements
General Matrix Multiply (GEMM)
Matrix multiplication is a key part of Neural Networks as part of the convolution layers. With weights held in one matrix and activations held in another:
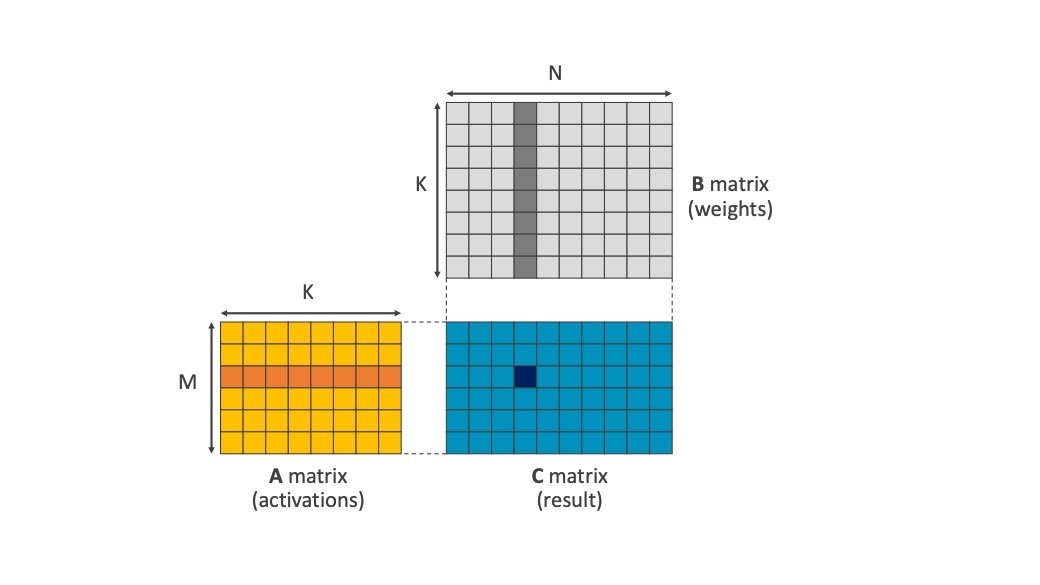
Figure 1 - Matrix multiply combining weights and activation, Arm Compute Library layout
To perform the matrix multiply, a simple algorithm typically uses three nested loops to compute one output at a time:

Total fetches needed: 2 * M * N * K
Armv8.6-A introduces new matrix multiply instructions to SVE and Neon. These optimize the process by reducing the number of memory accesses. This is achieved by computing multiple elements at once, for example:
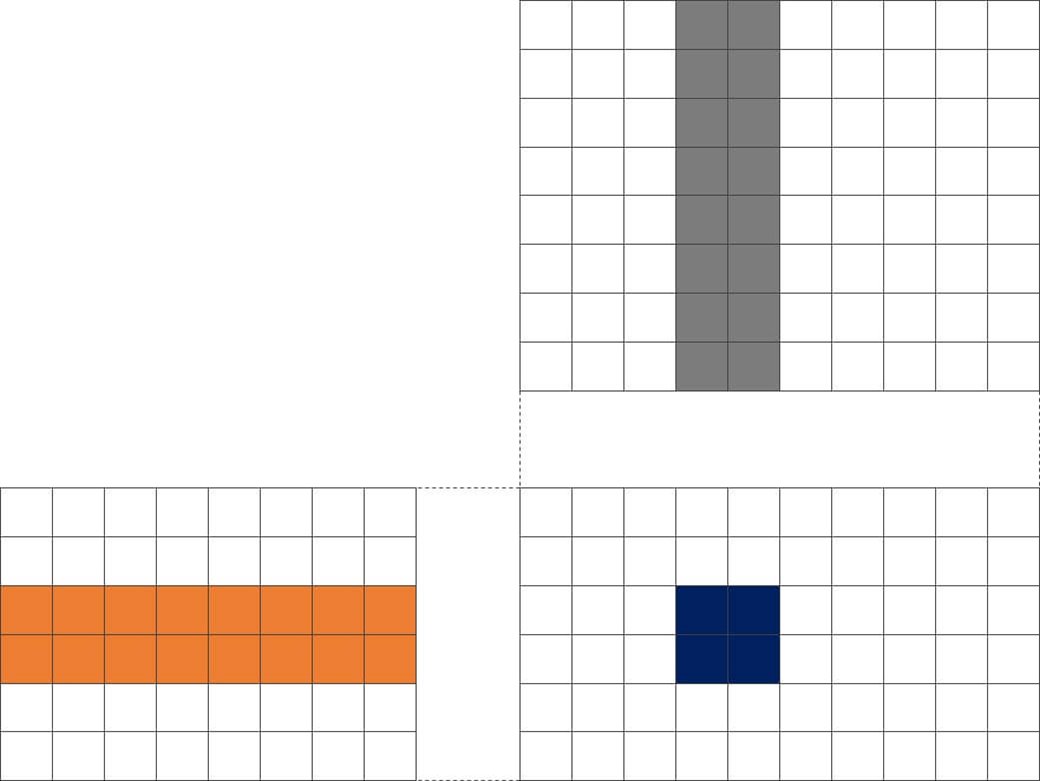
Figure 2 - Computing 2x2 elements at a time
Here we fetch two operands from A and B each time (2x fetches) but compute four results at a time (4x compute per loop; 4x fewer loops). Overall, fetch count is halved compared to computing one element at a time.
Larger areas offer larger benefits, for example with 4x4 array each depth iteration requires 8 operand values but performs 16 multiplies:
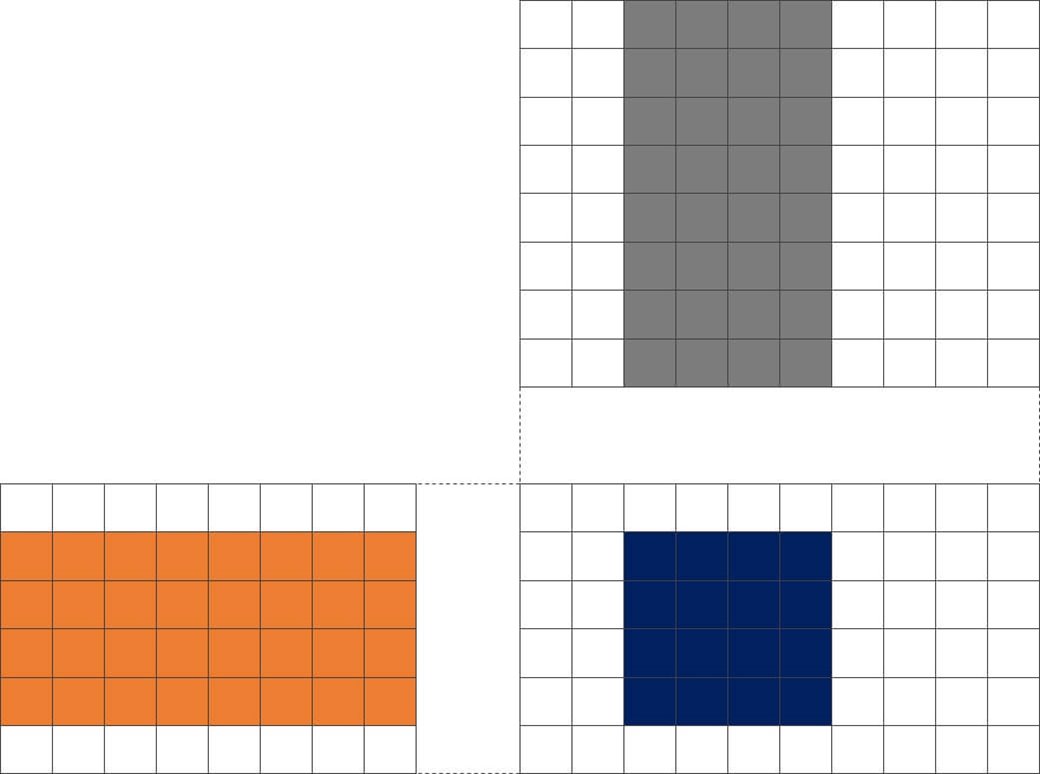
Figure 3 - Computing a 4x4 block of results
matrix multiply instructions for BFloat16 and signed or unsigned 8-bit integers is added to both SVE and Neon. SVE additionally supports single- and double-precision floating-point matrix multiplies.
BFloat16
BFloat16 (BF16) has recently emerged as a format tailored specifically to high-performance processing of Neural Networks. Armv8.6-A adds instructions to accelerate certain computations using the BF16 floating-point number format.
More information on Arm’s support for BF16 can be found in this neural network blog post.
Virtualization and system management-focused enhancements
Virtualization: Fine grained traps
Arm has continually improved virtualization support since it was first added in Armv7-A. A key feature of virtualization support is the ability to trap operations carried out by the virtual machine. Either to virtualize those operations or to allow the hypervisor to act as a sentinel for the Guest OS.
Armv8.6-A improves support for this second use-case, the hypervisor acting as sentinel. It does this by providing fine grained traps, covering individual system registers.
WFE traps
The Wait-for-Event (WFE) instructions allows an implementation to enter a low power state while waiting for an event, such as the release of a lock. Where the WFE is being executed by a virtual machine, a hypervisor will typically trap the WFE, allowing it to run a different workload.
Often the waited-for-event will arrive quickly, meaning that there can be a performance benefit to delaying taking the trap. Studies by Arm have shown that introducing a delay can improve throughput in over committed systems. To support this Armv8.6-A introduces optional support for a configurable delay in the trap being taken. Allowing software to tune the delay to the workload.
Generic Timer: High precision time
Since Armv7-A, Arm has provided a standardized timer framework, the Generic Timer architecture. Armv8.6-A introduces a series of improvements to the Generic Timer.
The Generic Timer provides a register, CNTFREQ_EL0, to report the system count frequency but allowed implementers freedom on what the frequency was. This could pose a challenge to software migrating workloads between systems with different frequencies. Armv8.6-A standardizes this frequency to 1GHz, giving a consistent time base. 1GHz is also a substantially higher frequency than previous guidelines, giving greater precision.
Additionally, self-synchronizing forms of the physical and virtual system count registers are added. This simplifies the code sequence needed, for example, to ensure a read of the current count comes after a memory operation.
Security
In Armv8.3-A and Armv8.5-A we introduced support for Pointer Authentication and Branch Target Indicators (BTI). Together these two features help mitigate against techniques such as ROP and JOP Attacks (Return- and Jump-Oriented Programming), by significantly reducing the number of gadgets available in a system.
Armv8.6-A builds upon this support further extending Pointer Authentication.
In Armv8.3-A, when authentication fails, an invalid address is returned. In most cases, that address will be used soon after the authentication instruction (AUT*), either to perform a branch or a data access. This use of the pointer results in an exception.
In some limited cases the address returned by the AUT* instruction is not immediately used, Armv8.6-A introduces two features to deal with these cases.
EnhancedPAC2
EnhancedPAC2 changes the way a PAC is added to a pointer. In Armv8.3-A, the PAC replaced the bits top bits of the pointer. With EnhancedPAC2, the PAC is XORed with the upper bits of the pointer.
FPAC
Where an attacker can gain access to the address returned by an AUT* instruction, they can potentially make repeated guesses at the correct PAC for the address.
To mitigate against such attacks, a new extension (FPAC) is added in Armv8.6-A. Implementations with FPAC generate an exception on an AUT* instruction where the PAC is incorrect. Preventing an attacker making multiple attempts to guess the correct PAC for a given address.
Other functionality
Armv8.6-A also includes other small features, including:
- A data gathering hint, to express situations where write merging is expected not to be performance optimal.
- Additional PMU events.
- Virtualization support added to Activity Monitor Units (AMU).
Summary
This blog provides a brief introduction to the latest features included in the Armv8-A architecture as Armv8.6-A. These features provide enhancements to future CPUs in the areas of neural networks for ML, virtualization, improved processing efficiency with matrix multiplication and security. The next step will be working with our ecosystem partners, including Linaro, to ensure that open source software is enabled, ready to make use of this functionality as soon as the hardware becomes available in a few years’ time.
For more detailed information, visit our Developer website.

Re-use is only permitted for informational and non-commerical or personal use only.
