Coding for Neon - Part 2: Dealing With Leftovers
In this post, we deal with an often encountered problem: input data that is not a multiple of the length of the vectors you want to process.
By Martyn

This blog has been updated and turned into a more formal guide on Arm Developer. You can find the latest guide here:
In part 1 of this series on Neon about loads and stores we looked at transferring data between the Neon processing unit and memory. In this post, we deal with an often encountered problem: input data that is not a multiple of the length of the vectors you want to process. You need to handle the leftover elements at the start or end of the array - what is the best way to do this on Neon?
Leftovers
Using Neon typically involves operating on vectors of data from four to sixteen elements in length. Frequently, you will find that your array is not a multiple of that length, and you have to process those leftover elements separately.
For example, you want to load, process and store eight elements per iteration using Neon, but your array is 21 elements long. The first two iterations go well, but for the third, there are only five elements remaining to be processed. What do you do?
Fixing Up
There are three ways to handle these leftovers. The methods vary in requirements, performance, and code size. They are listed below in order, with the fastest approach first.
Larger Arrays
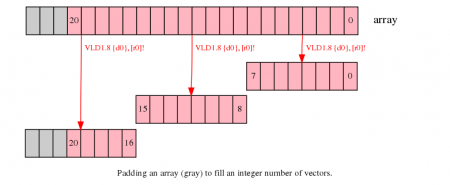
If you can change the size of the arrays that you are processing, increase the length of the array to the next multiple of the vector size using padding elements. This allows you to read and write beyond the end of your data without corrupting adjacent storage.
In the example above, increasing the array size to 24 elements allows the third iteration to complete without potential data corruption.
Notes
- Allocating larger arrays will consume more memory. The increase could be significant if many short arrays are involved.
- The new padding elements created at the end of the array may need to be initialized to a value that does not affect the result of the calculation. For example, if you are summing an array, the new elements must be initialized to zero for the result to be unaffected. If you are finding the minimum of an array, set the new elements to the maximum value an element can take.
- In some cases, it may not be possible to initialize the padding elements to a value that does not affect the result of a calculation - when finding the range of a set of numbers, for example.
Code Fragment
@ r0 = input array pointer
@ r1 = output array pointer
@ r2 = length of data in array
@ We can assume that the array length is greater than zero, is an integer
@ number of vectors, and is greater than or equal to the length of data
@ in the array.
add r2, r2, #7 @ add (vector length-1) to the data length
lsr r2, r2, #3 @ divide the length of the array by the length
@ of a vector, 8, to find the number of
@ vectors of data to be processed
loop:
subs r2, r2, #1 @ decrement the loop counter, and set flags
vld1.8 {d0}, [r0]! @ load eight elements from the array pointed to
@ by r0 into d0, and update r0 to point to the
@ next vector
...
... @ process the input in d0
...
vst1.8 {d0}, [r1]! @ write eight elements to the output array, and
@ update r1 to point to next vector
bne loop @ if r2 is not equal to 0, loop
Overlapping
If the operation is suitable, leftover elements can be handled using overlapping. This involves processing some of the elements in the array twice.
In the example case, the first iteration would process elements zero to seven, the second processes elements five to 12, and the third 13 to 20. Notice that elements five to seven, the overlap between the first and second vectors, have been processed twice.

Notes
- Overlapping can be used only when the operation applied to the input data does not vary with the number of times the operation is applied; the operation must be idempotent. For example, it can be used if you are trying to find the maximum element in an array. It can not be used if you are summing an array - the overlapped elements will be counted twice.
- The number of elements in the array must fill at least one complete vector.
Code Fragment
@ r0 = input array pointer
@ r1 = output array pointer
@ r2 = length of data in array
@ We can assume that the operation is idempotent, and the array is greater
@ than or equal to one vector long.
ands r3, r2, #7 @ calculate number of elements left over after
@ processing complete vectors using
@ data length & (vector length - 1)
beq loopsetup @ if the result of the ands is zero, the length
@ of the data is an integer number of vectors,
@ so there is no overlap, and processing can begin
@ at the loop
@ handle the first vector separately
vld1.8 {d0}, [r0], r3 @ load the first eight elements from the array,
@ and update the pointer by the number of elements
@ left over
...
... @ process the input in d0
...
vst1.8 {d0}, [r1], r3 @ write eight elements to the output array, and
@ update the pointer
@ now, set up the vector processing loop
loopsetup:
lsr r2, r2, #3 @ divide the length of the array by the length
@ of a vector, 8, to find the number of
@ vectors of data to be processed
@ the loop can now be executed as normal. the
@ first few elements of the first vector will
@ overlap with some of those processed above
loop:
subs r2, r2, #1 @ decrement the loop counter, and set flags
vld1.8 {d0}, [r0]! @ load eight elements from the array, and update
@ the pointer
...
... @ process the input in d0
...
vst1.8 {d0}, [r1]! @ write eight elements to the output array, and
@ update the pointer
bne loop @ if r2 is not equal to 0, loop
Single Elements
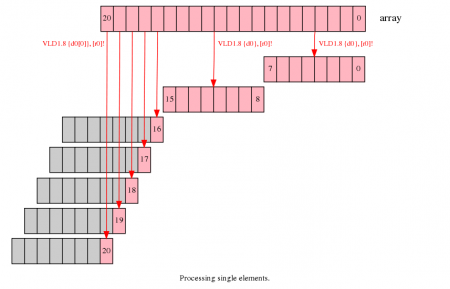
Neon provides loads and stores that can operate on single elements in a vector. Using these, you can load a partial vector containing one element, operate on it, and write the element back to memory.
For the example problem, the first two iterations execute as normal, processing elements zero to seven, and eight to 15. The third iteration needs only to process five elements. They are handled in a separate loop, which loads, processes and stores single elements.
Notes
- This approach is slower than the previous methods, as each element must be loaded, processed and stored individually.
- Handling leftovers like this requires two loops - one for the vectors, and a second for the single elements. This can double the amount of code in the function.
- Neon single element loads only change the value of the destination element, leaving the rest of the vector intact. If the calculation that you are vectorizing involves instructions that work across a vector, such as
VPADD, the register must be initiliazed before loading the first single element into it.
Code Fragment
@ r0 = input array pointer
@ r1 = output array pointer
@ r2 = length of data in array
lsrs r3, r2, #3 @ calculate the number of complete vectors to be
@ processed and set flags
beq singlesetup @ if there are zero complete vectors, branch to
@ the single element handling code
@ process vector loop
vectors:
subs r3, r3, #1 @ decrement the loop counter, and set flags
vld1.8 {d0}, [r0]! @ load eight elements from the array and update
@ the pointer
...
... @ process the input in d0
...
vst1.8 {d0}, [r1]! @ write eight elements to the output array, and
@ update the pointer
bne vectors @ if r3 is not equal to zero, loop
singlesetup:
ands r3, r2, #7 @ calculate the number of single elements to process
beq exit @ if the number of single elements is zero, branch
@ to exit
@ process single element loop
singles:
subs r3, r3, #1 @ decrement the loop counter, and set flags
vld1.8 {d0[0]}, [r0]! @ load single element into d0, and update the
@ pointer
...
... @ process the input in d0[0]
...
vst1.8 {d0[0]}, [r1]! @ write the single element to the output array,
@ and update the pointer
bne singles @ if r3 is not equal to zero, loop
exit:
Further Considerations
Beginning or End
The overlapping and single element techniques can be applied at the start or end of processing an array. The code above can be easily adapted to fix up elements at either end, if it is more suitable for your application.
Alignment
Load and store addresses should be aligned to cache lines, allowing more efficient memory accesses.
This requires at least 16-word alignment on Cortex-A8. If you can not align the start of your input and output arrays, you must handle elements at the beginning of processing an array (for alignment) and at the end of the array (for the incomplete final vector.)
When aligning memory accesses for speed, remember to use :64 or :128 or :256 address qualifiers with your load and store instructions, for optimum performance. You can compare the number of cycles required to issue a load or store using the data available in the Technical Reference Manual for your target core.
Here's the relevant page in the Cortex-A8 TRM.
Using Arm to Fix Up
In the single elements case, you could use Arm instructions to operate on each element. However, storing to the same area of memory with both Arm and Neon instructions can reduce performance, as the writes from the Arm pipeline are delayed until writes from the Neon pipeline have been completed.
Generally, you should avoid writing to the same area of memory (specifically, the same cache line) from both Arm and Neon code.
In the next post, we will look at a practical application of Neon: Matrix Multiplication.

By Martyn
Re-use is only permitted for informational and non-commerical or personal use only.
