Making Temporal Prefetchers Practical: The MISB Prefetcher
Temporal data prefetching usually introduces huge on- and off-chip storage and traffic overheads, making them impractical. However, a novel solution proposed by Arm Research and The University of Texas at Austin not only overcomes these issues, but also outperforms the state-of-the-art to make such prefetchers practical.

This blog post was co-authored with Dam Sunwoo.
Temporal data prefetching usually introduces huge on- and off-chip storage and traffic overheads, making them impractical. However, a novel solution proposed by Arm Research and The University of Texas at Austin not only overcomes these issues, but also outperforms the state-of-the-art to make such prefetchers practical.
Data Prefetching
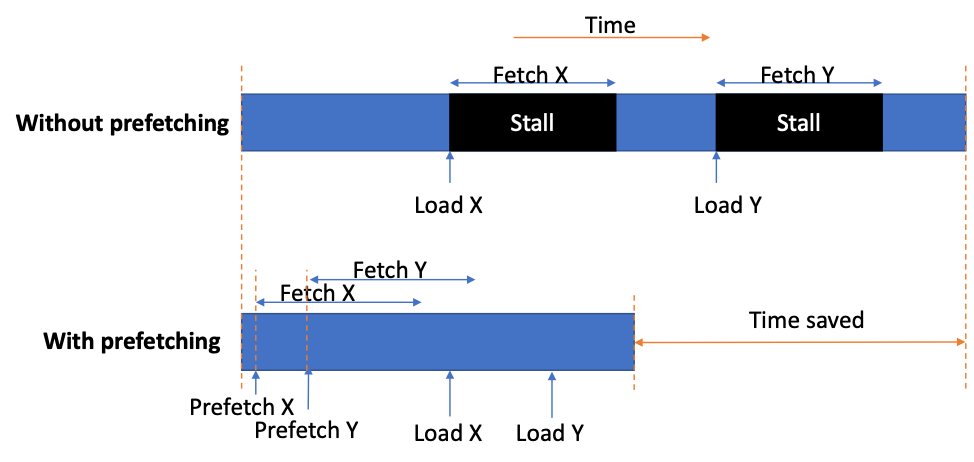
One of the biggest bottlenecks in processors is the long memory access latencies. While caches are effective in minimizing the number of times a processor accesses memory, some applications simply do not fit in the on-chip caches and end up frequently accessing the memory. These applications tend to spend a significant portion of their run times stalled on memory requests. Data prefetchers can help relieve this bottleneck by fetching the lines from memory and putting them in the caches before they are requested. Data prefetchers are now an integral part of any high-end processor contributing a significant portion to their single-thread and multi-thread performance.
Data prefetching reduces memory access latency
Hardware Data Prefetchers
Prefetching can be done either in software or hardware. Software prefetchers typically require programmers or compilers to insert prefetch instructions, while hardware prefetching is done completely in hardware and is transparent to the application. Hardware prefetchers observe the sequence of memory accesses at run-time, identify which memory addresses would be requested next, and bring them into the caches before the processor requests them.
Memory Access Patterns and Data Prefetcher Types
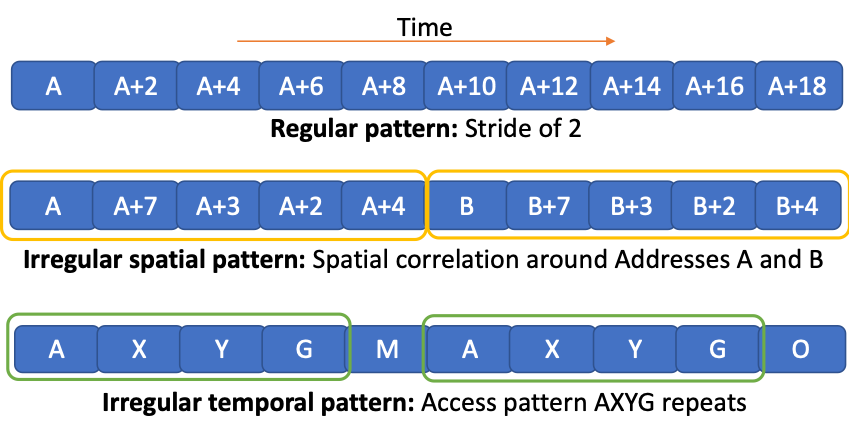
Hardware prefetching can generally be categorized into regular, irregular spatial and irregular temporal prefetching. The diagram below shows the different kinds of patterns targeted by these prefetchers. Stride and spatial prefetchers are currently being used in many commercial processors primarily because these prefetch engines are practical, i.e., they have relatively low storage overhead and are easy to implement.
On the other hand, temporal prefetcher proposals require huge on-chip storage overhead and dedicated off-chip metadata storage space, and also incur heavy off-chip traffic for accessing the metadata, thereby making them impractical. Our work published in ISCA 2019 [1] proposes a new temporal prefetcher, named MISB (Managed Irregular Stream Buffer), that mitigates these severe storage and traffic overheads and outperforms the state-of-the-art making temporal prefetchers practical.
Data prefetching targets different data patterns
Temporal Data Prefetchers
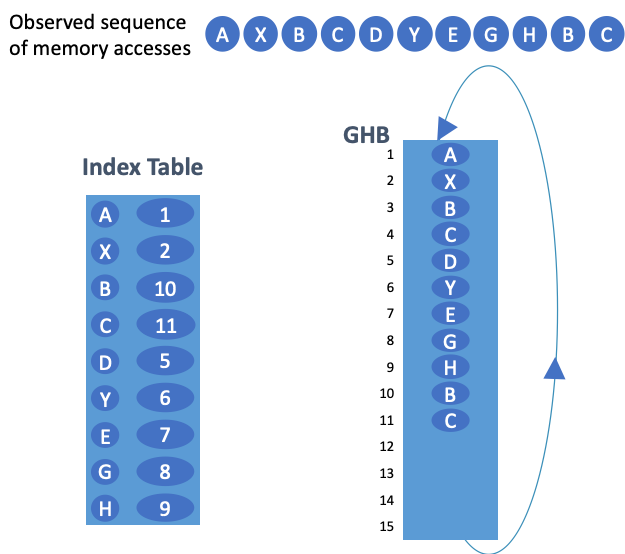
Temporal prefetchers typically record a sequence of memory accesses and prefetch them at a later time when the pattern repeats. Recent academic proposals such as STMS [2] and Domino [3] employ a global history buffer (GHB) and index table to record these memory accesses. For commercial applications these tables can grow to tens of megabytes and cannot be cached on-chip; hence this metadata is stored off-chip, i.e., in memory. The nature of GHB does not lend to caching, so every metadata access must go off-chip which incurs a high latency and also adds to the off-chip traffic. For some memory intensive applications, this traffic overhead can grow by several folds.
Temporal prefetching using a GHB
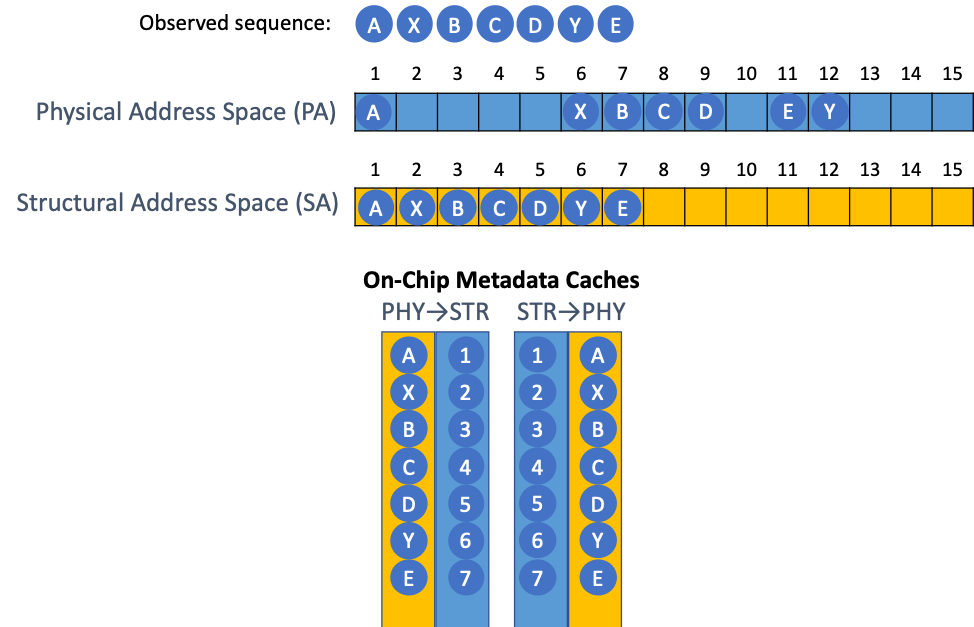
The ISB prefetcher published in MICRO 2013 [4] proposes a new way of managing the metadata. Every physical address is assigned a new structural address such that temporally correlated physical addresses will be present in consecutive structural addresses. This simplifies the process of prefetching to simply looking up the next structural address of a previously recorded sequence. Unlike GHB based metadata, the mappings between physical and structural address space do exhibit temporal locality and thus can be cached on-chip. This helps reduce the average metadata access latency drastically. ISB’s structural-address-space-based metadata also removes redundancies, which enables more efficient utilization of the available space both on- and off-chip. But ISB still suffers from huge off-chip traffic, poor metadata management, and high miss-rate in the on-chip metadata caches.
Our Proposal – MISB Prefetcher
We propose the MISB prefetcher which builds upon ISB by improving its metadata management. We propose three major improvements to ISB. First, we manage metadata at a finer granularity. This enables a more effective utilization of the on-chip metadata caches. Second, we significantly reduce the off-chip traffic by using a bloom filter to remove unnecessary metadata requests to memory. And third, our biggest contribution, introduces the concept of metadata prefetching. While a prefetch engine using a prefetcher to prefetch its own metadata may sound complicated, it is, in fact, quite simple and straightforward. Since streams of physical addresses reside in sequential addresses in the structural address space, once a stream is identified, we can simply prefetch the rest of the metadata for the stream to the on-chip metadata caches. This increases the hit-rate for the on-chip metadata caches and reduces the metadata access latency, thereby enabling timelier prefetches.
ISB introduces Structural Access Space
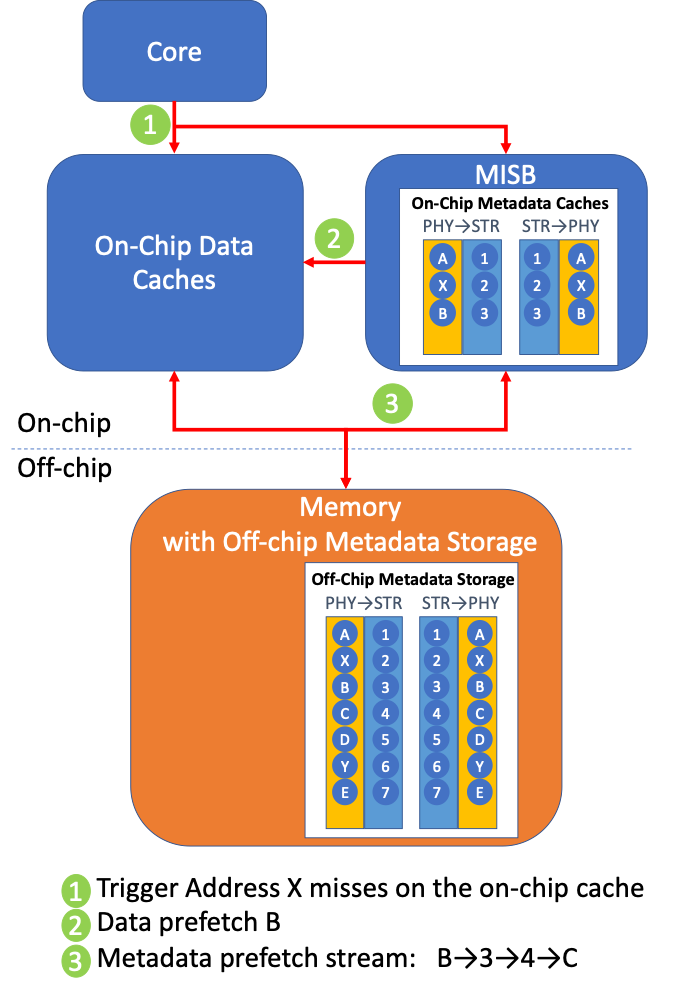
The figure below shows how our proposal works. MISB is trained on the stream of accesses to data-cache. In this example, the memory access X misses in the data cache. MISB then looks up the structural address for X in its on-chip metadata cache. The physical address X corresponds to the structural address 2. It then generates a data prefetch for the physical address corresponding to structural address 3 (2+1), i.e., address B.
MISB then tries to ensure that the next consecutive structural address is also available in the on-chip metadata caches so that, if there is a demand access for B next, we generate its corresponding data prefetch. In this case, we see that address B maps to structural address 3 and that the next structural address 4 is not available on-chip. So MISB generates a metadata prefetch to get the mappings and update them on-chip. This will prefetch the metadata mapping (4→C and C→4) to the on-chip structural-to-physical and physical-to-structural metadata caches.
Meta-data prefetching in MISB
MISB is the New State-of-the-art
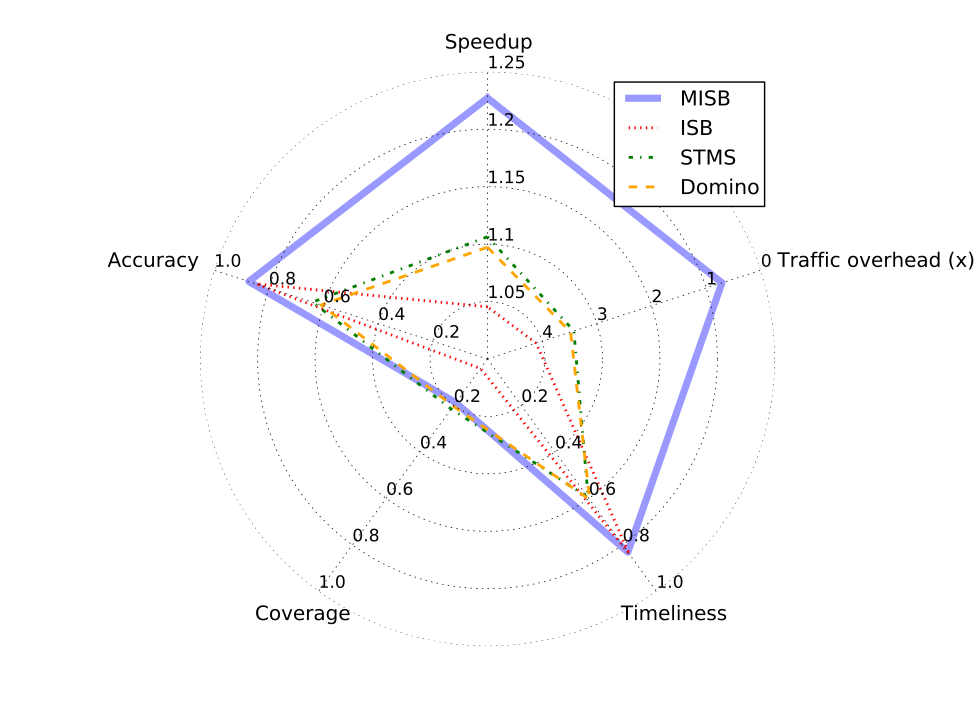
MISB outperforms the state-of-the-art academic prefetchers in almost all the categories on the irregular subset of SPEC CPU2006 benchmarks. MISB improves performance by 23%, while the STMS gets only 10.6% speedup. While STMS generates 4.8GB/s of traffic overhead MISB generates less than 1/4th the traffic overhead. In the figure below, we compare MISB against ISB and idealized versions of STMS and Domino (no access latency to off-chip metadata).
MISB compared to State of the Art
To learn more about the details of the MISB prefetcher, please read our ISCA 2019 paper below.
The MISB prefetcher takes us one step closer to a practical implementation of a temporal data prefetcher. We are continuing to investigate this research area, so look out for more publications from us in the near future. If you have any questions, comments, or suggestions, please feel free to reach out to us:
Contact Krishnendra Nathella Contact Dam Sunwoo
Acknowledgements
This work is the result of a collaboration with The University of Texas at Austin. The team consists of Hao Wu (former Arm Research intern from UT-Austin), Krishnendra Nathella and Dam Sunwoo from Arm Research, and Akanksha Jain and Professor Calvin Lin from the Computer Science department at UT Austin.
References
[1] Hao Wu, Krishnendra Nathella, Dam Sunwoo, Akanksha Jain, and Calvin Lin, “Efficient Metadata Management for Irregular Data Prefetching,” in Proceedings of the 46th Annual International Symposium on Computer Architecture (ISCA), 2019.
[2] Thomas. F. Wenisch, Michael Ferdman, Anastasia Ailamaki, Babak Falsafi, and Andreas Moshovos, “Practical off-chip meta-data for temporal memory streaming,” in Proceedings of the 15th International Symposium on High Performance Computer Architecture (HPCA), 2009.
[3] Mohammad Bakhshalipour, Pejman Lotfi-Kamran, and Hamid Sarbazi-Azad, “Domino temporal data prefetcher,” in Proceedings of the 24th IEEE International Symposium on High Performance Computer Architecture (HPCA), 2018.
[4] Akanksha Jain and Calvin Lin, “Linearizing irregular memory accesses for improved cor- related prefetching,” in Proceedings of the 46th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2013.

Re-use is only permitted for informational and non-commerical or personal use only.
