Porting PuTTY to Windows on Arm
An in-depth look on porting PuTTY to Windows on Arm. Traditionally, programs like this have only ever been run on x86 machines. Simon Tatham explains how he got his side project PuTTY running on a Windows on Arm machine, and optimized the cryptography code using the Arm v8 Crypto Extension.
By Simon Tatham

In my day job, I work in the Arm Development Solutions Group, developing Arm Compiler and its supporting tools. In my spare time, I’m also the lead developer of the free SSH client PuTTY.
Recently, Windows on Arm has been making a splash, so last year I did a little porting work to get WoA builds of PuTTY. This year, I’ve gone a little further, and optimised the cryptography code using the Arm v8 Cryptographic Extension. So the next release of PuTTY (expected this month) should contain all of that work.
That was all done in my spare time, but since I also work for Arm, they asked if I could write something up about how all that was done.
Building an application for Windows on Arm
Of course, the first job was to compile PuTTY for WoA at all. As of Visual Studio 2017 (and also 2015, which I was still using at the start of this project), if you try to compile an ordinary Win32 desktop application with the Arm-targeted VS compiler, you find that its header files don’t define most of the API functions by default, so you get a lot of compile-time errors. The solution (found on the Internet) is to compile with a magic #define, namely _ARM_WINAPI_PARTITION_DESKTOP_SDK_AVAILABLE, which turns on all those parts of the headers.
The next job was to fix any PuTTY-specific compile failures or runtime bugs. I guessed that the cross-platform parts of the code would have no trouble here, because Linux distributions have been compiling those on Arm for years. But the Windows front end had never before been built for any architecture except x86, and even the move to x86-64 needed a lot of bug fixes, so I was definitely expecting that there would be some work needed here.
In fact, there wasn’t! Once I added that macro definition to the makefile, the whole tool suite built first time for Windows, and nobody has yet reported any bug specific to the WoA build.
So that was a very encouraging start. But I wasn’t quite finished, because Visual Studio isn’t actually the compiler I use for the production builds of PuTTY: instead, for various reasons, I use clang-cl in VS emulation mode (a choice also made by the Chromium project). So the next question was, would it be just as easy to build for WoA using clang?
Answer: nearly as easy. There was one small wrinkle, which was stack protection. On x86, clang’s stack protection is compatible with Visual Studio’s C library, but when targeting Arm, I found that clang emitted references to __stack_chk_guard and __stack_chk_fail, which are part of a stack protection system that’s not the same as the one VS uses. The VS-compatible stack protection involves functions called __security_push_cookie and __security_pop_cookie, and clang doesn’t know how to generate calls to those. So I had to turn off stack protection (/GS-) on the command line.
But after that, everything worked fine, and clang-built Windows PuTTY was running on Arm!
Building the installer
After building the PuTTY executable files, there’s one more thing done by the master build script: wrapping them into an MSI installer.
There are two problems with doing that. One is that many MSIs, including PuTTY’s, do some of their install-time activities by embedding a DLL, and having the MSI database tables include an instruction that says ‘now call a function in this DLL’. PuTTY’s installer uses this to validate the install directory when the user selects it interactively, and to display the README file after installation. To run an MSI on Arm, I had no idea what architecture those DLLs should be built for.
Rather than spend a lot of effort finding out, I thought an easier approach was just to get rid of the DLLs completely. Both the things we use them for are minor quality-of-implementation issues, and don’t make the installer unusable if you just leave them out. So for the Arm MSI, I just conditioned them out.
The other problem is that an MSI has a master table including a ‘platform’ field, and initially, I couldn’t work out what to put in there. If I set it to ‘Arm’ or ‘Arm64’, then msiexec.exe reported that the installer was for an unsupported platform! ‘x86-64’ was also refused, leaving only ‘x86’ – and if I set it to ‘x86’, then when msiexec ran the installer, it insisted on installing the Arm PuTTY executable files in C:\Program Files (x86).
That one took some actual help from Microsoft to solve. (Thanks, Microsoft, if you're reading this!) It turned out that the answer is that you also have to adjust the InstallerVersion property on the Package element in the WiX input file: following previous example code, I had it set to 100 (for x86) or 200 (for x86-64), but if you set it to 500, then that tells msiexec to switch to a schema in which the platform ‘Arm64’ is legal. Phew.
Accelerated cryptography
Last year, a contributor sent us code to implement some of PuTTY’s usual cryptographic algorithms – the AES cipher, and the SHA-256 and SHA-1 hash functions – using the dedicated x86 instructions designed to accelerate those algorithms.
Arm also has hardware acceleration for those same algorithms, in the Arm v8 crypto extension to NEON. Now that PuTTY is running on WoA, it seemed a shame not to have a parallel set of accelerated implementations for NEON. I was able to do this without having to write any actual assembly – it was enough to write the code using the NEON data types and intrinsic functions defined by ACLE, which means the same C source code can compile for either AArch32 or AArch64 (because the intrinsics are named consistently across both).
To set this up, you start by adding #include <arm_neon.h> to your source file, which defines a set of vector types with names like uint32x4_t (a vector of 4 32-bit integers) and uint8x16_t (sixteen 8-bit bytes), and a set of intrinsics – i.e. functions that operate on those types, and more or less map one-to-one with the NEON vector instructions. For example, vaddq_u32(a,b) takes two uint32x4_t vectors, and returns a uint32x4_t vector in which each 32-bit lane contains the sum of the corresponding input lanes.
ACLE is a standard that should apply to all Arm-targeted compilers – gcc, clang and Visual Studio alike. In fact, I found it wasn’t quite that simple (on Visual Studio targeting AArch64, I had to include <arm64_neon.h> instead of <arm_neon.h>, and a couple of other compiler/platform combinations aren’t quite working for me at the moment), but in principle, this should work everywhere.
AES
The AES block cipher is well suited to NEON, because it operates on a block of 128 bits at a time – exactly the size of a NEON vector register – and consists of a series of transformations that change those 128 bits into a new 128 bits.
The nice thing about implementing AES using hardware acceleration is that it’s not necessary to worry about every single detail of the cipher (as you have to if you’re implementing it in pure software). So I don’t have to explain it in full detail here, either: I only have to mention the basic components of the algorithm and how they match up to the NEON instructions.
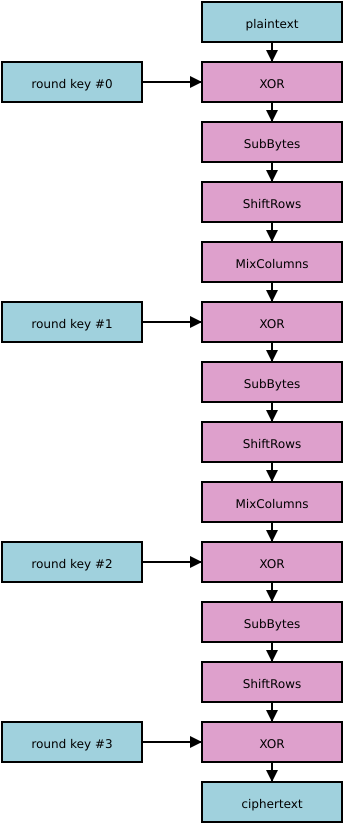
The AES encryption process consists of a sequence of rounds, which jumble up the cipher state. The round function itself is fixed (it doesn’t depend on the cipher key); but in between every pair of rounds, before the first round, and after the final round, the cipher state is XORed with 128 bits of data derived from the key. (This is often referred to as ‘addition’ in the AES spec, even though it’s XOR to most programmers, because it corresponds to the addition operation of the finite field that AES is based on.)
The round function is broken up into three conceptual pieces: SubBytes, which transforms each individual byte of the state according to a fixed substitution; ShiftRows, which reorders the 16 bytes of the state but leaves their values alone; and MixColumns, which combines the bytes with each other in groups of four. Each round consists of those three operations in order, except for the last round, which omits the MixColumns step.
Here’s a diagram that shows what AES would look like if it had only three rounds. In fact it has at least 10 (depending on key size), but the diagram would just look like more of the same if I put them all in:
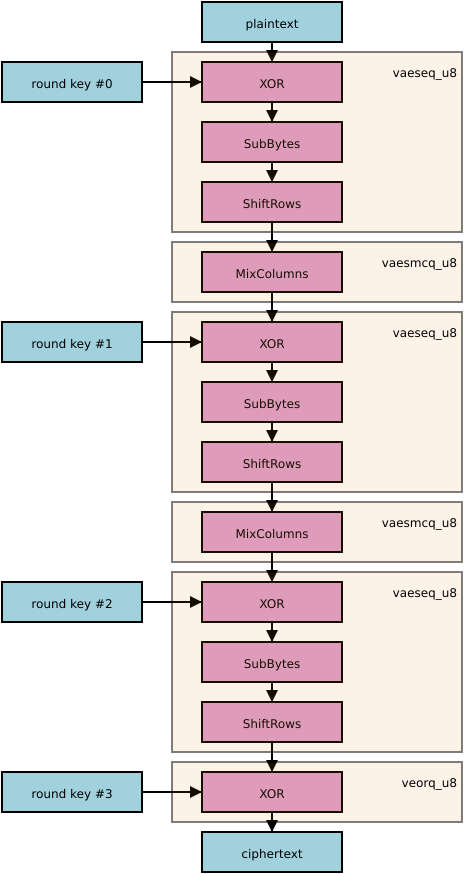
NEON provides two instructions to accelerate AES encryption: AESE and AESMC, which are wrapped by the C intrinsic functions vaeseq_u8 and vaesmcq_u8.
vaeseq_u8 bundles together the addition of the round key, SubBytes and ShiftRows. So it takes two inputs (the cipher state and the round key), and vaeseq_u8(s,k) returns ShiftRows(SubBytes(s XOR k)). The other intrinsic, vaesmcq_u8, takes a single input vector and performs MixColumns on it.
So most AES rounds consist of one call to each of these intrinsics, with vaesmcq_u8 coming second. The final round omits MixColumns, so it’s just vaeseq_u8 on its own – but then you have to add the last round key, which is done by the ordinary non-crypto NEON intrinsic veorq_u8.
So here’s the same diagram again, showing what the NEON instructions are that do all the same jobs:
And here’s a simple implementation in working C:
/* roundkeys[] is an array containing n_rounds + 1 elements */
uint8x16_t aes_encrypt(uint8x16_t plaintext,
const uint8x16_t roundkeys[],
unsigned n_rounds)
{
uint8x16_t state = plaintext;
/* All but the last round */
for (unsigned i = 0; i < n_rounds-1; i++) {
state = vaeseq_u8(state, roundkeys[i]);
state = vaesmcq_u8(state);
}
/* The last round, without MixColumns */
state = vaeseq_u8(state, roundkeys[n_rounds-1]);
/* XOR in the final round key */
state = veorq_u8(state, roundkeys[n_rounds]);
}
Simple as that! Who said cryptography was hard?
The basic decryption routine looks exactly the same, except that you use vaesdq_u8 in place of vaeseq_u8 (which uses the inverted version of the SubBytes transformation), and vaesimcq_u8 in place of vaesmcq_u8 (again, the inverse transformation).
If you refer back to the diagram above, you’ll notice that that doesn’t exactly perform the same operations in reverse order. SubBytes and ShiftRows are the other way round, for a start, but that doesn’t make any difference because they’re independent of each other anyway and can be done in either order. But also, each of the inner round key additions (that is, all but the first and last) has moved to the other side of a MixColumns operation. That does make a difference, but it’s a difference you can compensate for when you set up the roundkeys[] array in the first place ... which is what I’m going to talk about next.
When the user sets up AES, they provide 128, 192 or 256 bits of data as the official key. But the encryption process needs 128 bits per round, and there are 10, 12 or 14 rounds depending on the key length. So the key has to be expanded into a ‘key schedule’ containing all the individual round keys, and the key schedule is a vital part of the cipher design and implementation.
In AES, the key schedule is specified as a sequence of 32-bit words. The first few words of the schedule are simply the input key itself (either 4, 6 or 8 words depending on the key size). After that, each schedule word is derived from two of the previous words, with various transformations applied; you keep doing that until you have enough key material for all the round keys (that is, 4 × (rounds + 1) words), and then you group the words together in batches of 4.
For my purposes, I wasn’t interested in seriously optimising the key schedule setup. In SSH, you only set up an AES key when you’ve just done a public-key operation, and any public-key operation takes many times as long as even a slow AES key expansion, so it wouldn’t be worth bothering. So I didn’t worry about whether it might be possible to vectorise the key expansion and generate the schedule words in batches of 2 or 4; I just plod along generating each individual word one at a time, and combine them into vectors once I’ve finished. That’s more than fast enough for this application.
One of the transformations you need during key setup is exactly the same SubBytes operation that is one of the phases of encryption – but you have to apply it on its own to just one 32-bit word at a time. We’d like to use the vaeseq_u8 intrinsic to do that for you; but that bundles up SubBytes with two other operations, which now we have to compensate for.
One of the other operations is adding a round key. That’s easily solved: just pass a zero vector as the other operand to vaeseq_u8, and that becomes a no-op.
The other operation done by vaeseq_u8 is ShiftRows, which (as I said above) reorders the 16 bytes of the cipher state. More specifically, suppose the bytes start off looking like this:

The effect of ShiftRows is to leave all the A bytes fixed; cycle the B bytes round by one place to the left, the C bytes round by two, and the D by three. So you end up with this:

The nice thing about this is that every A slot is still occupied by an A byte, and similarly for B,C,D. And we only need to apply SubBytes to one 32-bit word. So if we make all the A bytes the same as each other, and likewise B,C,D, then you end up with a vector containing four copies of the input 32-bit value:

and if you apply ShiftRows to a vector of that form, it leaves it completely unchanged.
So you can perform a stand-alone SubBytes operation on a 32-bit word by making a vector of four copies of it (using the vdupq_n_u32() intrinsic), and then using that as one of the inputs to vaeseq_u8(), with the other one being an all-zeroes vector. Then the round key addition and the ShiftRows become no-ops, and the output vector has four copies of exactly the word you wanted.
In fact there are a few more administrative details, like the fact that vdupq_n_u32() returns a value whose C type is uint32x4_t, whereas vaeseq_u8() wants a uint8x16_t as input. The approved way to convert between them is to use vreinterpretq_u8_u32(), which generates no actual code (the vector register is unchanged) and just tells C to start treating it as a different type. With that and the code to extract a single uint32_t word from the output vector, I ended up having to do this to get my SubBytes:
uint32_t standalone_SubBytes(uint32_t input_word)
{
uint32x4_t v32 = vdupq_n_u32(input_word);
uint8x16_t v8 = vreinterpretq_u8_u32(v32);
v8 = vaeseq_u8(v8, vdupq_n_u8(0));
v32 = vreinterpretq_u32_u8(v8);
return vget_lane_u32(vget_low_u32(v32), 0);
}
(Different compilers vary in whether they actually need you to use vreinterpretq. I initially compiled my prototype code with clang, which doesn’t mind at all if you pass an intrinsic a different vector type – it didn’t even give me a warning. But when I tried to build it with gcc, which does mind, I got lots of type errors, and had to go back and reinsert all the vreinterpretqs. So if you’re writing NEON code, make sure your code compiles with gcc before anyone else tries it!)
The other operations you need in key setup are to rotate a word left by 8 bits, and to XOR together two words of the key schedule and sometimes XOR in a constant as well. Of course, doing those things to a 32-bit word at a time doesn’t need any NEON at all.
Once you’ve got your complete list of 32-bit words, you can combine them into the uint8x16_t vectors needed by the encryption routine by using vld1q_u32 to load a batch of four words, and then another vreinterpretq_u8_u32 to turn the result into the right type.
Finally, I mentioned above that decryption needs all but the first and last round keys to be modified to account for them being moved to the other side of a MixColumns operation. Specifically, you just have to apply vaesimcq_u8 to each one; then you rearrange them into the opposite order, and that’s a version of the key schedule you can use for decryption.
So that’s how you do AES in NEON!
SHA-256
Right, on to hash functions!
Of the two hashes accelerated by the v8 crypto extension, SHA-256 is the more modern one and also the easier one to work with, because its internal state is 256 bits long and fits nicely into two NEON vector registers.
The main component of SHA-256, and the one that NEON can accelerate, is an update function which takes a 256-bit hash state and a 64-byte block of the message, and returns an updated version of the hash state. Outside that, there’s a layer of padding and marshalling that tells you how to translate an arbitrary-length message into a series of 64-byte blocks, and what the initial value of the hash state should be, but that can all be done in conventional code without needing special-purpose acceleration.
The update function consists of two main parts. Firstly, the input message block is expanded into a ‘message schedule’ consisting of 64 32-bit words, starting with the 16 words of the message itself, followed by another 48 that are derived from it. Secondly, each word of the message schedule is used as input to a ‘round’ of the main hash operation, which updates the 256-bit hash state based on that schedule word.
(Structurally, this is very like a block cipher, with the input message corresponding to the key, the message schedule being the list of round keys, the input hash value being the plaintext, and the updated hash value the ciphertext. But the tradeoffs change about how much complexity you put in each component, because in a block cipher you make a key schedule once and then use it for many cipher blocks, whereas in a hash function each schedule you make is a one-off.)
So the simplest way to write SHA-256 in ordinary unaccelerated code is to separate the two stages completely, and write two separate loops. In pseudocode (leaving out the details of how the updates are actually done):
uint32_t schedule[64];
// Make schedule
for (i = 0; i < 16; i++)
schedule[i] = load_bigendian_32bit(message + 4*i);
for (i = 16; i < 64; i++)
schedule[i] = make_new_schedule_word(previous words);
// Consume schedule
for (i = 0; i < 64; i++)
hash_state = hash_update(hash_state, schedule[i]);
So, how does NEON help us with this?
Each new schedule word is made from a combination of some previous schedule words, and they’re always the same distances back in the stream: schedule[i] is constructed from schedule[i-2], schedule[i-16] and a couple in between. So the schedule construction loop never needs to look further back than 16 words.
The NEON acceleration for SHA-256 provides a pair of instructions which deliver a full vector of 4 new words of the message schedule, given four vector registers full of the previous 16 words. (There have to be two instructions involved, so that they can have enough input registers between them.)
So in NEON, you can build the message schedule as a sequence of uint32x4_t vectors, like this:
uint32x4_t sched[16];
for (i = 0; i < 4; i++)
sched[i] = vreinterpretq_u32_u8(vrev32q_u8(
vld1q_u8(message + 16*i)));
for (i = 4; i < 16; i++)
sched[i] = vsha256su1q_u32(vsha256su0q_u32(
sched[i-4], sched[i-3]), sched[i-2], sched[i-1]);
SHA-256 specifies that the input message is regarded as a sequence of big-endian 32-bit words, so – assuming little-endian Arm, which is what we expect to see on both Linux and Windows – we have to use vrev32q_u8 to byte-reverse each word, and then a vreinterpretq to turn the output of that into the right vector type.
The part that does the heavy lifting is the second loop. vsha256su0q_u32 takes two vectors of schedule data from further back in the stream, extracts as much information from them as the next instruction will need, and packs that into a single output vector. Then vsha256su1q_u32 takes that intermediate value plus the other two vectors of recent schedule data, and delivers the full and complete output schedule.
For the second loop that updates the hash state, NEON again provides two instructions which between them perform four rounds of the hash. But they don’t quite do the whole job by themselves, because SHA-256 also specifies a different 32-bit constant for each round, which is added to the message schedule word before the main operation. (That ensures that some mixing still happens even if the input message block was something really boring like all zeroes.)
So in order to perform four rounds of SHA-256, you need a vector of message schedule, plus a vector of the round constants for those four rounds, and you start by adding them together (this time using real addition, unlike AES):
uint32x4_t round_input = vaddq_u32(
schedule[i], round_constant_vectors[i]);
Having done that, you can now use the dedicated SHA-256 instructions to update the actual hash state:
new.abcd = vsha256hq_u32 (old.abcd, old.efgh, round_input);
new.efgh = vsha256h2q_u32(old.efgh, old.abcd, round_input);
I’ve given the two hash-state vectors the names abcd and efgh, because the SHA-256 specification describes the state as consisting of eight 32-bit words called a,b,c,d,e,f,g,h, so this keeps the correspondence clear between the spec and the implementation.
Note in particular that both the update instructions must receive the old values of the state vectors – it won’t work if you overwrite one vector with its updated value and then pass that as input to the other instruction. Also note that the two intrinsics take the old state vectors opposite ways round in their argument lists!
So you could write a NEON SHA-256 implementation by combining those snippets of code in the same way as before: first loop round making an array of 16 vectors of message schedule, then loop over that array adding in the round constants and updating the hash state.
But we can do better. Because the schedule update function only needs four previous vectors of state, there’s no real need to store the whole message schedule in an array. We can save time by interleaving the two loops, so that we generate each word of message schedule and then immediately consume it.
So you could do this kind of thing instead:
uint32_t sched[4];
struct { uint32_t abcd, efgh; } hash_state;
for (int i = 0; i < 4; i++) {
sched[i] = vreinterpretq_u32_u8(vrev32q_u8(
vld1q_u8(message + 16*i)));
hash_state = hash_update(
hash_state, schedule[i], round_constants[i]);
}
for (int i = 4; i < 16; i++) {
sched[i] = vsha256su1q_u32(vsha256su0q_u32(
sched[ i ], sched[(i+1)%4]),
sched[(i+2)%4], sched[(i+3)%4]);
hash_state = hash_update(
hash_state, schedule[i], round_constants[i]);
}
in which hash_update() is an inline subfunction wrapping the addition of the round constants and the hash update instructions. Now sched[] is only four vectors long instead of 16, and it stores the previous four vectors in a cyclically rotating fashion, so that every time round the second loop, the new schedule vector is stored over the top of the least recently written one.
In my actual code, I’ve unrolled both of those loops completely, expanded out the array indices in sched[], and turned it into four independent uint32x4_t variables, just to make sure the compiler realises that it’s better to keep all four in registers throughout the function.
SHA-1
The older hash function SHA-1 is essentially similar in structure to SHA-256. In particular, it has the same separation into generating the message schedule and consuming it, and again, you could write those loops separately but we prefer to interleave them.
The two main differences are that SHA-1 has a hash state consisting of only five 32-bit words instead of eight, and also that its rounds come in three slightly different types, each of which has a separate NEON instruction.
(The three types are called ‘choice’, ‘majority’ and ‘parity’, named after the ternary Boolean function that each one uses during its operation, so the NEON intrinsics are called vsha1cq_u32, vsha1mq_u32 and vsha1pq_u32. There are 80 rounds in total, consisting of 20 × c, 20 × p, 20 × m and finally 20 × p again. Also, a smaller difference from SHA-256 is that each batch of 20 rounds uses a single constant throughout, instead of varying it in every round as SHA-256 does.)
Because of the five-word structure, the hash state is represented in C as a mismatched pair of variables, again named to reflect the correspondence with the variable names in the SHA-1 spec:
uint32x4_t abcd;
uint32_t e;
Although e has an ordinary integer type, the underlying NEON instructions will need it to be stored in a floating-point register. So to get this hash to perform well, it’s extra important to not pass e across any real function-call boundaries, where the procedure call standard would force it to be moved into an integer register and back. We want to make sure it’s all done in a single function, and any subroutines you use for code clarity will have to be labelled ‘inline’.
The schedule update for SHA-1 looks almost exactly like SHA-256: it still takes four previous vectors of schedule as input and delivers the next whole vector as output. But it so happens that this time it’s the first-stage update intrinsic (vsha1su0q_u32) that takes three arguments, and the second one (vsha1su1q_u32) takes two:
uint32x4_t sched[16];
for (i = 0; i < 4; i++)
sched[i] = vreinterpretq_u32_u8(vrev32q_u8(vld1q_u8(
message + 16*i)));
for (i = 4; i < 16; i++)
sched[i] = vsha1su1q_u32(vsha1su0q_u32(
sched[i-4], sched[i-3], sched[i-2]), sched[i-1]);
(You almost can’t see the difference, written like this! The only effect is that the closing parenthesis in the last line comes after schedule[i-2], whereas it came after schedule[i-3] in SHA-256.)
The round update still adds a constant to the schedule vector, and then performs two instructions to deliver the updated version of the state. But one of those instructions (delivering the output abcd vector) has to vary depending on the type of the round; the other one (delivering e) is the same instruction in all round types, but the complication is that it expects just one lane of the abcd vector as input. So you have to combine it with a couple of extra NEON intrinsics to extract that lane from the uint32x4_t.
So an example of a full SHA-1 round looks like this:
uint32x4_t round_input = vaddq_u32(schedule[i], round_constant);
new.abcd = vsha1cq_u32(old.abcd, old.e, round_input);
new.e = vsha1h_u32(vget_lane_u32(vget_low_u32(old.abcd), 0));
and then you also need modified versions which switch the abcd update to use vsha1mq_u32 or vsha1pq_u32.
(The vget_lane business should optimise away when the code is compiled, because the compiler will just select the 32-bit FP register overlapping the appropriate lane of the input vector.)
As with SHA-256, it makes more sense to interleave the schedule generation and consumption, to avoid the need to load and store everything into an intermediate array on the stack, and to space apart the loads from the message.
Further possibilities
All of this has got us to the point of having working implementations of AES, SHA-256 and SHA-1 using NEON acceleration.
Those implementations will already be faster than pure software implementations of the same primitives. So after I’d got this much working in PuTTY, I decided it was a reasonable stopping point, and moved on to some other unrelated fixes.
But if you want to optimise further, there are still things that can be done.
Many cipher modes, such as SDCTR, are parallelisable, in the sense that you can feed multiple blocks of data through the main cipher without a dependency between them. The NEON AES instructions are not intrinsically parallel – they can only process one block at a time – but if you’re using a parallelisable cipher mode, then it’s probably still a win to have a function that decrypts 4 or 8 cipher blocks at a time, loading each round key vector just once and applying it to lots of vector registers containing the intermediate states of many separate blocks.
Other cipher modes don’t parallelise. For example, CBC encryption needs to know each output cipher block in order to XOR it into the next plaintext block, so you can’t avoid having to encrypt your blocks one at a time. (However, CBC decryption is parallelisable.) But even there, you can find a trick or two to squeeze out more performance, using the fact that CBC is based on the same operation (XOR) as the round key additions in AES: if, instead of XORing each plaintext block with the previous ciphertext block, you XOR it with the value from just before the final veorq_u8 adds in the last round key, and compensate for the error by using a modified initial round key which is the XOR of the first and last normal ones, then you can get the veorq_u8 off the critical path that blocks the next cipher iteration from starting.
(Of course, you can’t get rid of the veorq completely. It’s still needed to produce the output version of each ciphertext block, of course. It’s just that, on a multiple-issue CPU, now the next encryption operation can be getting started while the veorq is still working.)
I don’t know of any analogous optimisations you can do with SHA-256 and SHA-1, but I wouldn’t be surprised if there were some to be found there as well. Maybe one day I’ll come back and try to tune all of this for even higher performance!

By Simon Tatham
Re-use is only permitted for informational and non-commerical or personal use only.
