Running Llama 3 70B on the AWS Graviton4 CPU with Human Readable Performance
In this blog post, we compare the performance of AWS Graviton4 and AWS Graviton3 for running LLMs, and demonstrate how Llama 3 70B can be run with human readable performance on AWS Graviton4
By Na Li

| This blog post was co-authored by Na Li and Masoud Koleini. |
Amazon Web Services (AWS) introduced its latest generation of custom-designed Arm-based CPUs, the AWS Graviton4 processors, which became generally available on July 9, 2024. These state-of-the-art processors are developed using the Arm Neoverse V2 core, based on the 64-bit Arm instruction set architecture. This architecture positions Graviton4 as a highly efficient and powerful solution for a variety of cloud-based applications [1].
In our analysis, we assessed the inferencing performance of language models on AWS EC2 instances powered by Graviton4 processors, specifically the C8g instance types. We ran models ranging from 3.8 billion to 70 billion parameters [2-5], utilizing Q_4_0_4_8 quantization techniques optimized for Arm kernels, and used llama.cpp for benchmarking [6]. Additionally, we performed comparative evaluations by running models on Graviton4-powered instances and comparing them to EC2 instances with the previous generation Graviton3 processors.
The 70B Llama model, known for its computational intensity, was successfully deployed on CPUs using quantization techniques, achieving a token generation rate faster than human readability, at 5-10 tokens per second. Graviton4 instances provided the flexibility to support models up to 70 billion parameters, a capacity that Graviton3 instances could not accommodate.
Llama 3 70B performs faster than human readability on AWS Graviton4
The AWS Graviton4 processor provides potential capability for executing larger-scale language models compared with their predecessor Graviton3. To assess the performance of Graviton4 processor in running different parameter sizes of LLMs, we deployed three models — the Llama 3 70B, Phi3-Mini 3.8B, and Llama 3 8B — on the Graviton4 C8g.16xlarge instance and we measured its inferencing performance. The primary performance metric was the latency of next-token generation, as illustrated in Figure 1. Although the Llama 3 70B model exhibited higher latency relative to the smaller models, it still achieved a human readability level of 5-10 tokens per second with batch size of 1, closely meeting the target service-level agreement (SLA) of 100ms for next token generation latency.
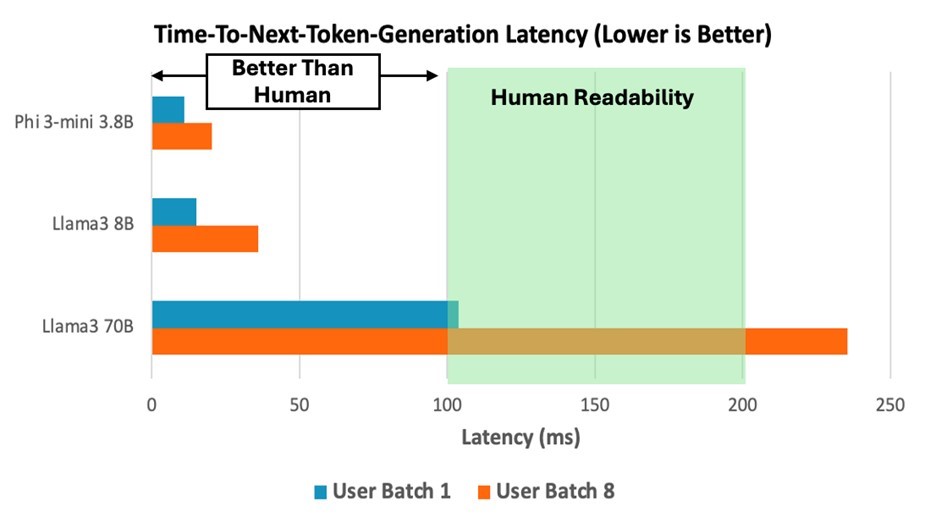 Figure 1: Performance of time-to-next-token-generation of running Llama 3 70B, Phi3-Mini 3.8B, and Llama 3 8B models on C8g.16xlarge instance. The batch size simulates the scenario where one or multiple users call the model simultaneously.
Figure 1: Performance of time-to-next-token-generation of running Llama 3 70B, Phi3-Mini 3.8B, and Llama 3 8B models on C8g.16xlarge instance. The batch size simulates the scenario where one or multiple users call the model simultaneously.
According to Meta [7], the Llama 3 70B model exhibits outstanding performance in the tasks that demand advanced logical reasoning (see examples in Image 1), although it has higher latency of next token generation compared to the Llama 3 8B model (Figure 1). For applications where low-latency response times are critical but require less complex logical reasoning, the Llama 3 8B model is a suitable option. Conversely, if the application allows for more flexibility in latency but requires high-level reasoning or creative capabilities, the Llama 3 70B model can be an appropriate choice.

Figure 1: The top row shows an example where both Llama 3 8B and models produce a good answer for a question which is knowledge based; while the bottom row shows an example where only Llama 3 70B produces a correct answer since the solution to the question requires logic reasoning.
Supporting different language models with Graviton3 and Graviton4 processors
To assess the performance of AWS Graviton processors in running language models (LLMs), we deployed various models ranging from 3.8 billion to 70 billion parameters on the Graviton3 (C7g.16xlarge) and Graviton4 (C8g.16xlarge) instances and measured their inference capabilities.
As detailed in Table 1, both Graviton3 and Graviton4-based instances are capable of supporting models up to 27 billion parameters, including Phi 3-mini 3.8B, Llama 3 8B, and Gemma 2 27B. However, Graviton4 is able to manage the largest model evaluated, the Llama 3 70B.

Table 1: Support of various language models with Graviton3 and Graviton4 processors.
Performance improvement from Graviton3 to Graviton4 processors
To evaluate performance enhancements, we deployed the Llama 3 model (8 billion parameters) on both the Graviton3 (C7g.16xlarge) and Graviton4 (C8g.16xlarge) instances. Performance was assessed based on prompt encoding, which measures the speed at which user inputs are processed and interpreted by the language model, as illustrated in Figure 2. The Graviton4 consistently exhibited performance improvements in prompt encoding for all tested user batch sizes, achieving a 14-26% improvement (Figure 2, right axis).
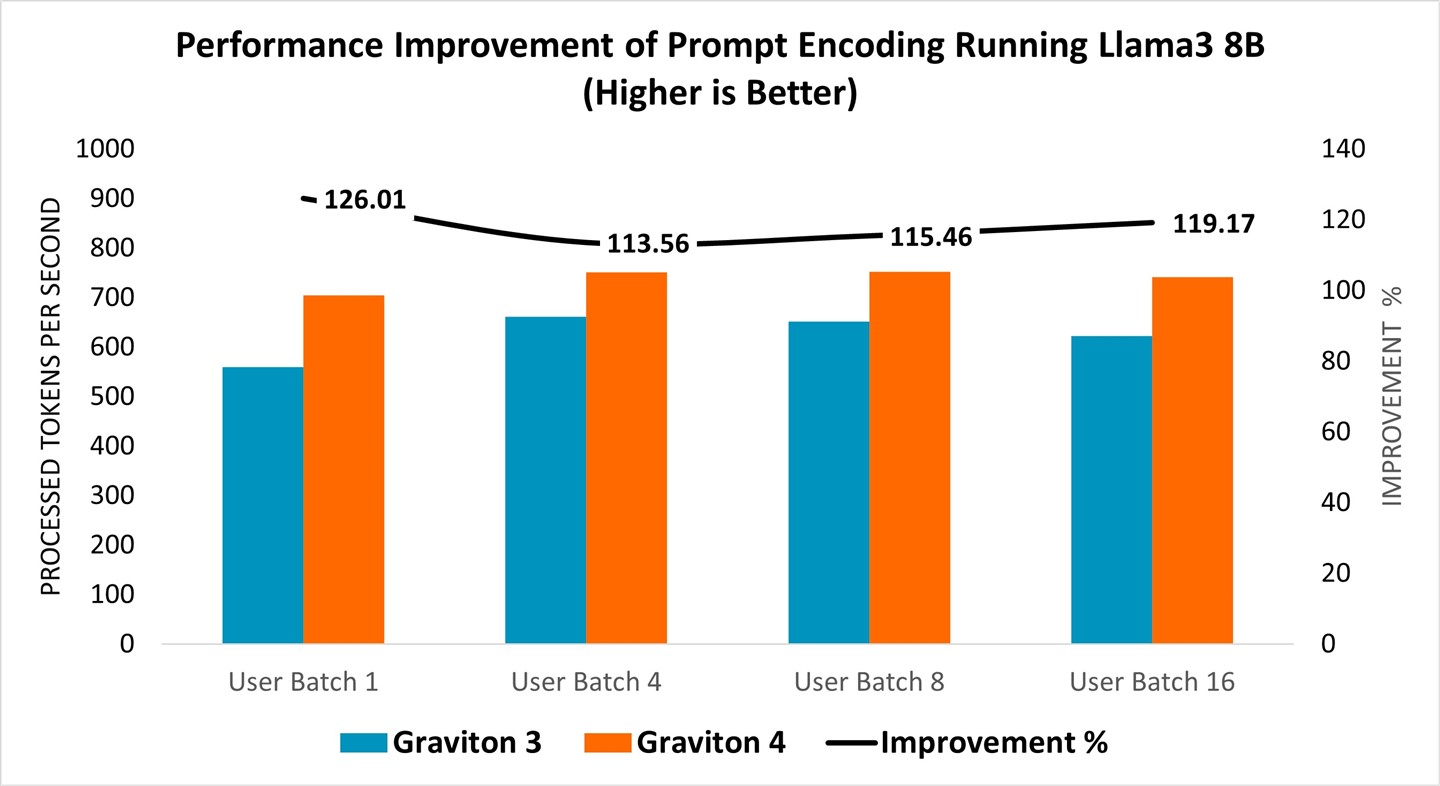
Figure 2: Performance improvement of prompt encoding running Llama 3 8B model from Graviton3 (C7g.16xlarge) to Graviton4 (C8g.16xlarge).
Token generation, which assesses the speed at which the language model responds and produces text when running Llama 3 8B, as depicted in Figure 3, also demonstrated significant gains. The performance curve revealed a marked improvement for all tested user batch sizes, with the Graviton4 displaying more substantial efficiency gains at smaller user batch sizes, achieving 5-50% improvement (Figure 3, right axis).
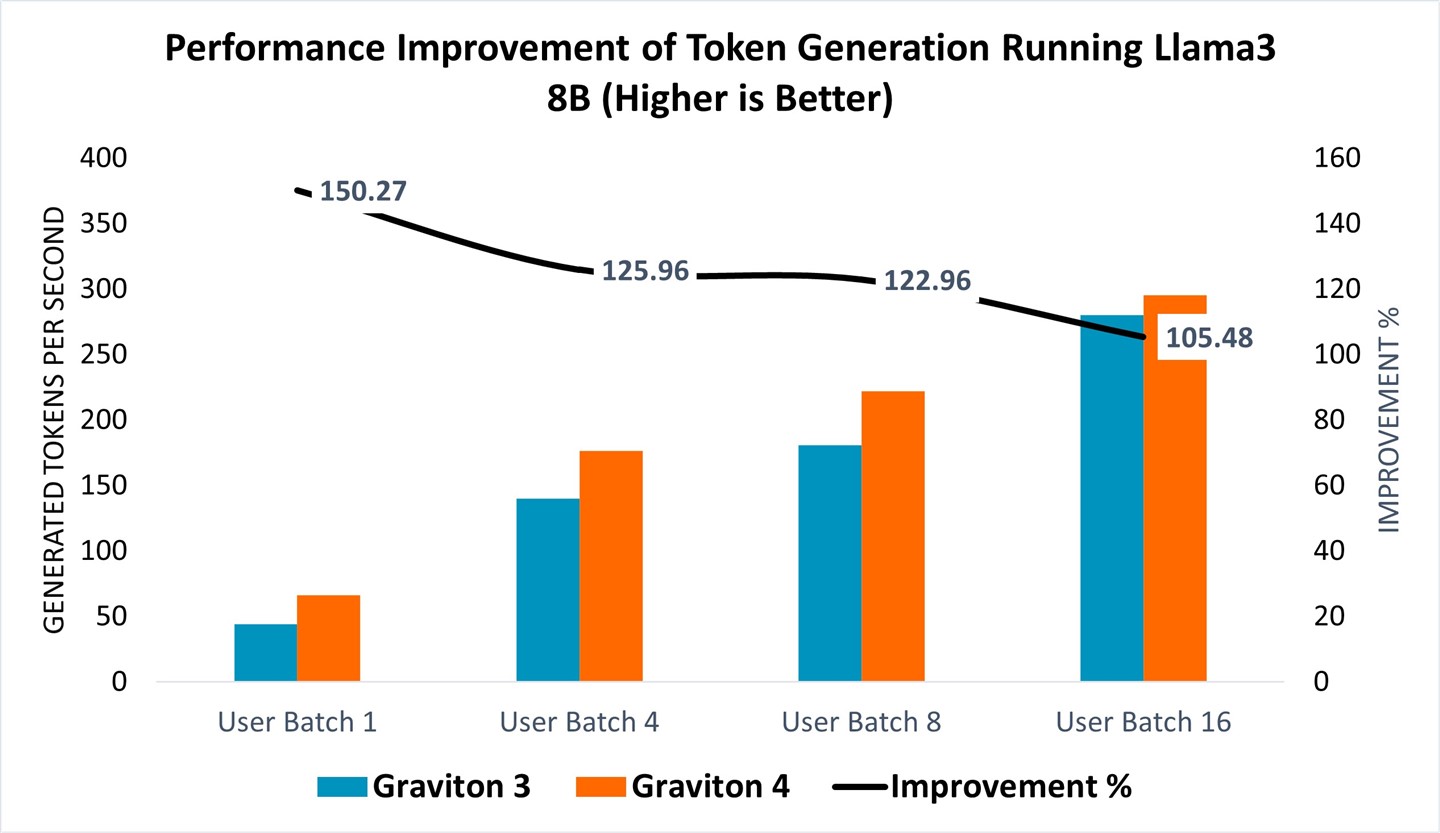
Figure 3: Performance improvement of token generation running Llama 3 8B model from Graviton 3 (C7g.16xlarge) to Graviton 4 (C8g.16xlarge).
Conclusion
Running Llama 3 70B on an AWS Graviton4 C8g.x16large instance exceeds human readability levels by generating 10 tokens per second. This enhanced performance enables Graviton4 to handle a broader range of generative AI tasks, including those requiring advanced reasoning, compared to Graviton3. When running a Llama 3 8B model, Graviton4 demonstrates a 14-26% improvement in prompt encoding and a 5-50% boost in token generation over Graviton3. To explore this performance further, you can try the demo available in the learning path: https://learn.arm.com/learning-paths/servers-and-cloud-computing/llama-cpu/_demo.
References:
- https://aws.amazon.com/ec2/graviton/
- https://huggingface.co/NousResearch/Meta-Llama-3-70B-GGUF/resolve/main/Meta-Llama-3-70B-Q4_K_M.gguf
- https://huggingface.co/bartowski/gemma-2-27b-it-GGUF/resolve/main/gemma-2-27b-it-Q4_K_S.gguf
- https://huggingface.co/QuantFactory/Meta-Llama-3-8B-GGUF/resolve/main/Meta-Llama-3-8B.Q4_0.gguf
- https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/Phi-3-mini-4k-instruct-q4.gguf
- https://github.com/ggerganov/llama.cpp (Release: b3440)
- https://ai.meta.com/blog/meta-llama-3/
By Na Li
Re-use is only permitted for informational and non-commerical or personal use only.
