Measuring the impact of branch prediction for Cortex-R7 and Cortex-R8
How to measure the impact of branch prediction for Cortex-R7 and Cortex-R8.
The ARM® Cortex®-R7 and Cortex-R8 processors are the most advanced processors for modem and storage designs. One of the great things about the ARM architecture is the software compatibility between different cores. This is great for software reuse, but it can be challenging to identify differences between the various Cortex-R family members. For example, consider a design using the Cortex-R4 or Cortex-R5 and upgrading to the Cortex-R7 or Cortex-R8. The compatibility of the ARMv7-R architecture means the software will be compatible, but there will be some important differences. An example of this is branch prediction. ARM Cycles Models provide a good way to look at the impact of branch prediction on the Cortex-R8.
Introduction to branch prediction
Branch prediction is used in microprocessors to anticipate program flow with the goal of pipeline efficiency. There are many ways to implement branch prediction, and there is usually a trade-off between better prediction results and increased hardware to do the prediction.
The Cortex-R8 uses both static and dynamic branch prediction techniques. Static branch prediction is based on decoding instructions and can be used on new code that has not been executed before, but because decisions come later in the pipeline there is not as much time to speculatively fetch code at the branch target address.
Dynamic branch prediction can be used when code has been executed before. The Cortex-R8 will speculatively fetch instructions based on execution history. Dynamic branch prediction will predict:
- Whether there is a branch instruction at a given address
- Unconditional and conditional branches
- Loops, function call, or function return
- Target address and/or state of destination (ARM/Thumb)
- Direction of conditional branch (taken or not taken)
Dynamic branch prediction uses an extra memory buffer to keep track of history.
Branch prediction is generally a good thing, and like caches the hardware provides improved performance without software needing to pay much attention. The main task of system software to make sure the maximum benefit of the hardware is realized.
Enabling branch prediction
One of the key things to understand when writing software for a CPU is what kind of programming is required to get the best performance. Some hardware features for performance improvement are automatically enabled, but can be disabled by software. Other features start disabled, and can be enabled to improve performance. Many times features may start disabled because special care is required to enable them, such as invalidating a cache.
In the early days of providing cycle accurate models for ARM CPUs, the most common user question was how to enable caches. Architects were interested in doing performance analysis and just wanted to run the CPU at its maximum performance and see what happened. They didn’t always have experience to figure out how to do the low-level programming required to configure the CPU for best performance. Branch prediction is similar, and this is why all ARM Cycle Models come with example software to help with the hardware configuration.
The branch prediction feature in the Cortex-R4 and Cortex-R5 is automatically enabled at reset. There is nothing software needs to do to get the maximum performance from this feature. However, the Cortex-R7 and Cortex-R8 do not enable branch prediction automatically at reset. This means software must enable branch prediction to get the maximum hardware performance.
A good place to get the details of hardware programming is in the DS-5 examples/ directory. The file Bare-metal_examples_ARMv7.zip contains example startup code for many different CPUs. Extracting the file and looking at the code for each CPU provides insight into how to make sure the maximum performance is realized. The file startup_Cortex-R8/startup.s shows how to set the Z bit to enable branch prediction.
The Z bit is located in the system control register, SCTLR, and is bit 11.

The example code to enable branch prediction is below.
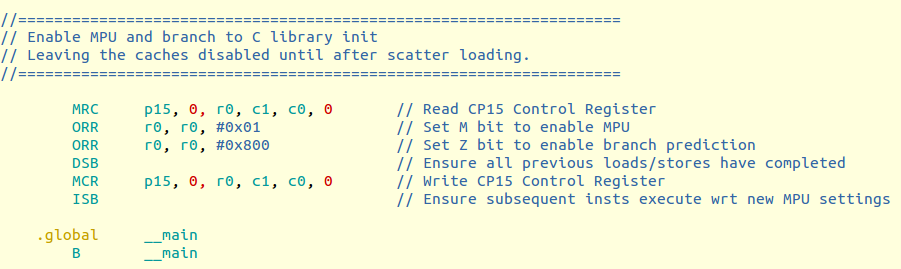
This means that it is important to make sure branch prediction is enabled when a previous product which used Cortex-R4 or Cortex-R5 migrates to Cortex-R7 or Cortex-R8. Although this sounds easy, it’s not obvious for two reasons. First, without any action the software will “just work” across different CPUs. Second, there is no single place to see “what’s different” when comparing CPU A to CPU B. Providing such information is only relative to which CPUs are being compared and many ARM CPUs make incremental improvements so it’s a bit of a hunt to identify differences.
Benchmarking results
The impact of branch prediction can be evaluated using Cycle Models. The general technique to measure performance using Cycle Models is to run to a breakpoint which represents an interesting place to start profiling and enable profiling. Then continue execution to another breakpoint which represents the end of the interesting code. At the second breakpoint, turn off profiling and study the results.
All of this can be scripted and automated if needed to gather results using different compiler optimization switches.
To start things off, build the software to run, with and without branch prediction enabled. Run the Cortex-R8 CPAK and use a software debugger to set a breakpoint on the interesting starting point. Cycle Models allow connections from any software which supports CADI including modeldebugger and DS-5.

At the end of the interesting section of code, look at the metrics. The simplest thing for measuring the impact of branch prediction is how many simulation cycles were required to run the same software. If branch prediction is helping, the cycle count will be less.
A Cortex-R8 quad-core CPAK was used to experiment with branch prediction for the CPU. It can be run on either Windows or Linux using SoC Designer. For more details of this and other CPAKs visit ARM System Exchange.
To evaluate the impact of branch prediction, dhrystone, CoreMark, and whetstone were run with and without branch prediction enabled. The table below shows the number of cycles required to run the same code with and without branch prediction.
|
Branch prediction off |
Branch prediction on |
|
|
Dhrystone cycle count |
380,240 cycles |
155,675 cycles |
|
Coremark cycle count |
1,123, 107 cycles |
580,431 cycles |
|
Whetstone cycle count |
22,143,393 cycles |
15,535,307 cycles |
SoC Designer offers easy, non-intrusive performance analysis features to inspect PMU events, bus activity, and software execution.
Below are two views of the branch prediction PMU events. The first is for CoreMark with branch predication off and the second is the same CoreMark with branch prediction on. The mis-predicts are very large without setting the Z-bit to a 1 and very low when the Z-bit is set to 1. The numbers in the "Total" column represent the total number of events for the entire simulation. Click on the graphs to get a better view.
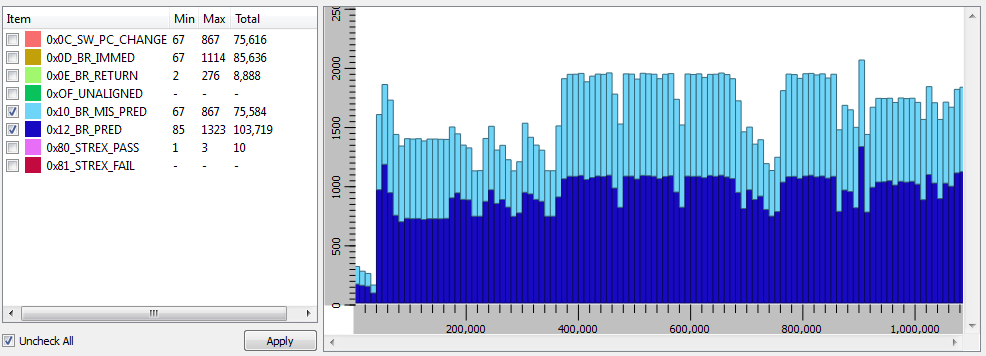
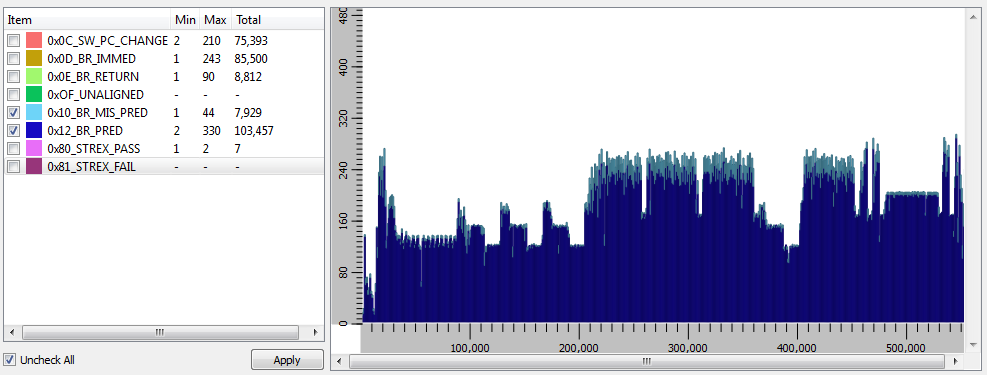
Many other events can also be captured using the profiling features of SoC Designer.
Conclusion
ARM Cycle Models can be used to study a variety of system changes. Common uses are comparing different CPUs, experimenting with cache size or branch prediction, analyzing memory subsystem design, and more. The impact of Cortex-R8 branch prediction on three benchmarks was demonstrated and the importance of making sure all hardware features are enabled for best performance was highlighted.

Re-use is only permitted for informational and non-commerical or personal use only.
